Excel-ark er meget instinktive og brugervenlige, hvilket gør dem ideelle til at manipulere store datasæt selv for mindre tekniske folk. Hvis du leder efter steder at lære at manipulere og automatisere ting i Excel-filer ved hjælp af Python , stop med at lede. Du er på det rigtige sted.
I denne artikel lærer du, hvordan du bruger Pandaer at arbejde med Excel-regneark. I denne artikel lærer vi om:
- Læs Excel fil bruge Pandas i Python
- Installation og import af pandaer
- Læsning af flere Excel-ark ved hjælp af Pandas
- Anvendelse af forskellige Pandas funktioner
Læsning af Excel-fil ved hjælp af Pandas i Python
Installation af pandaer
For at installere Pandas i Python kan vi bruge følgende kommando i kommandoprompten:
pip install pandas>
For at installere Pandas i Anaconda kan vi bruge følgende kommando i Anaconda Terminal:
conda install pandas>
Import af pandaer
Først og fremmest skal vi importere Pandas-modulet, hvilket kan gøres ved at køre kommandoen:
Python3
import> pandas as pd> |
>
>
Input fil: Lad os antage, at Excel-filen ser sådan ud
Ark 1:

Ark 1
Ark 2:
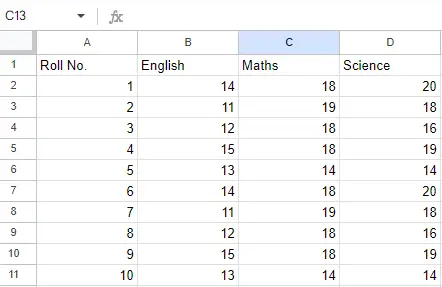
Ark 2
Nu kan vi importere Excel-filen ved hjælp af read_excel-funktionen i Pandas for at læse Excel-fil ved hjælp af Pandas i Python. Den anden sætning læser dataene fra Excel og gemmer dem i en pandas Data Frame, som er repræsenteret af variablen newData.
Python3
df>=> pd.read_excel(>'Example.xlsx'>)> print>(df)> |
>
>
Produktion:
Roll No. English Maths Science 0 1 19 13 17 1 2 14 20 18 2 3 15 18 19 3 4 13 14 14 4 5 17 16 20 5 6 19 13 17 6 7 14 20 18 7 8 15 18 19 8 9 13 14 14 9 10 17 16 20>
Indlæsning af flere ark ved hjælp af Concat()-metoden
Hvis der er flere ark i Excel-projektmappen, importerer kommandoen data fra det første ark. For at lave en dataramme med alle arkene i projektmappen er den nemmeste metode at oprette forskellige datarammer separat og derefter sammenkæde dem. Read_excel-metoden tager argumentet sheet_name og index_col, hvor vi kan angive det ark, som rammen skal være lavet af, og index_col angiver titelkolonnen, som vist nedenfor:
Eksempel:
Den tredje sætning sammenkæder begge ark. Nu for at kontrollere hele datarammen, kan vi blot køre følgende kommando:
java hale
Python3
file> => 'Example.xlsx'> sheet1>=> pd.read_excel(>file>,> >sheet_name>=> 0>,> >index_col>=> 0>)> sheet2>=> pd.read_excel(>file>,> >sheet_name>=> 1>,> >index_col>=> 0>)> # concatinating both the sheets> newData>=> pd.concat([sheet1, sheet2])> print>(newData)> |
>
>
Produktion:
Roll No. English Maths Science 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 6 19 13 17 7 14 20 18 8 15 18 19 9 13 14 14 10 17 16 20 1 14 18 20 2 11 19 18 3 12 18 16 4 15 18 19 5 13 14 14 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Head() og Tail() metoder i Pandas
For at se 5 kolonner fra toppen og fra bunden af datarammen kan vi køre kommandoen. Det her hoved() og hale() metode tager også argumenter som tal for antallet af kolonner, der skal vises.
Python3
print>(newData.head())> print>(newData.tail())> |
>
>
Produktion:
English Maths Science Roll No. 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 English Maths Science Roll No. 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Shape() metode
Det form() metode kan bruges til at se antallet af rækker og kolonner i datarammen som følger:
Python3
newData.shape> |
>
>
Produktion:
(20, 3)>
Sort_values() metode i Pandas
Hvis en kolonne indeholder numeriske data, kan vi sortere den kolonne ved hjælp af sort_værdier() metode i pandaer som følger:
Python3
java liste node
sorted_column>=> newData.sort_values([>'English'>], ascending>=> False>)> |
>
>
Lad os nu antage, at vi vil have de øverste 5 værdier i den sorterede kolonne, vi kan bruge head() metoden her:
Python3
sorted_column.head(>5>)> |
>
>
Produktion:
English Maths Science Roll No. 1 19 13 17 6 19 13 17 5 17 16 20 10 17 16 20 3 15 18 19>
Vi kan gøre det med enhver numerisk kolonne i datarammen som vist nedenfor:
Python3
java software mønstre
newData[>'Maths'>].head()> |
>
>
Produktion:
Roll No. 1 13 2 20 3 18 4 14 5 16 Name: Maths, dtype: int64>
Pandas Describe() metode
Antag nu, at vores data for det meste er numeriske. Vi kan få de statistiske oplysninger som middelværdi, max, min osv. om datarammen ved hjælp af beskrive() metode som vist nedenfor:
Python3
newData.describe()> |
>
>
Produktion:
English Maths Science count 20.00000 20.000000 20.000000 mean 14.30000 16.800000 17.500000 std 2.29645 2.330575 2.164304 min 11.00000 13.000000 14.000000 25% 13.00000 14.000000 16.000000 50% 14.00000 18.000000 18.000000 75% 15.00000 18.000000 19.000000 max 19.00000 20.000000 20.000000>
Dette kan også gøres separat for alle de numeriske kolonner ved hjælp af følgende kommando:
Python3
newData[>'English'>].mean()> |
>
er proteinfedt
>
Produktion:
14.3>
Andre statistiske oplysninger kan også beregnes ved hjælp af de respektive metoder. Ligesom i Excel kan formler også anvendes, og beregnede kolonner kan oprettes som følger:
Python3
newData[>'Total Marks'>]>=> >newData[>'English'>]>+> newData[>'Maths'>]>+> newData[>'Science'>]> newData[>'Total Marks'>].head()> |
>
>
Produktion:
Roll No. 1 49 2 52 3 52 4 41 5 53 Name: Total Marks, dtype: int64>
Efter at have opereret på dataene i datarammen, kan vi eksportere dataene tilbage til en Excel-fil ved hjælp af metoden to_excel. Til dette skal vi specificere en output Excel-fil, hvor de transformerede data skal skrives, som vist nedenfor:
Python3
newData.to_excel(>'Output File.xlsx'>)> |
>
>
Produktion:
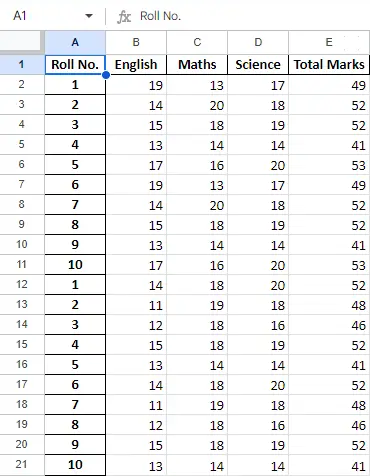
Slutark