BERT, et akronym for tovejskoderrepræsentationer fra transformere , står som en open source maskinlæringsramme designet til riget af naturlig sprogbehandling (NLP) . Denne ramme stammer fra 2018 og er lavet af forskere fra Google AI Language. Artiklen har til formål at udforske arkitektur, arbejde og anvendelser af BERT .
Hvad er BERT?
BERT (Bidirectional Encoder Representations from Transformers) udnytter et transformer-baseret neuralt netværk til at forstå og generere menneskelignende sprog. BERT anvender en encoder-only-arkitektur. I originalen Transformer arkitektur , er der både encoder- og dekodermoduler. Beslutningen om at bruge en encoder-only-arkitektur i BERT foreslår en primær vægt på at forstå inputsekvenser i stedet for at generere outputsekvenser.
Bidirektionel tilgang af BERT
Traditionelle sprogmodeller behandler tekst sekventielt, enten fra venstre mod højre eller højre mod venstre. Denne metode begrænser modellens bevidsthed til den umiddelbare kontekst, der går forud for målordet. BERT bruger en tovejstilgang, der tager hensyn til både venstre og højre kontekst af ord i en sætning, i stedet for at analysere teksten sekventielt, ser BERT på alle ordene i en sætning samtidigt.
Eksempel: Banken ligger på _______ af floden.
I en ensrettet model vil forståelsen af blanketten i høj grad afhænge af de foregående ord, og modellen kan have svært ved at skelne, om banken refererer til en finansiel institution eller siden af floden.
BERT, der er tovejs, betragter samtidig både venstre (Breden ligger på) og højre kontekst (af floden), hvilket muliggør en mere nuanceret forståelse. Det forstår, at det manglende ord sandsynligvis er relateret til bankens geografiske placering, hvilket demonstrerer den kontekstuelle rigdom, som den tovejstilgang bringer.
Fortræning og finjustering
BERT-modellen gennemgår en to-trins proces:
- Fortræning i store mængder umærket tekst for at lære kontekstuelle indlejringer.
- Finjustering af mærkede data til specifikke NLP opgaver.
Foruddannelse i store data
- BERT er fortrænet på store mængder umærkede tekstdata. Modellen lærer kontekstuelle indlejringer, som er repræsentationer af ord, der tager hensyn til deres omgivende kontekst i en sætning.
- BERT engagerer sig i forskellige uovervågede fortræningsopgaver. For eksempel kan det lære at forudsige manglende ord i en sætning (Masked Language Model eller MLM-opgave), forstå forholdet mellem to sætninger eller forudsige den næste sætning i et par.
Finjustering af mærkede data
- Efter fortræningsfasen finjusteres BERT-modellen, bevæbnet med dens kontekstuelle indlejringer, til specifikke NLP-opgaver (natural language processing). Dette trin skræddersyer modellen til mere målrettede applikationer ved at tilpasse dens generelle sprogforståelse til nuancerne i den særlige opgave.
- BERT finjusteres ved hjælp af mærkede data, der er specifikke for downstream-opgaver af interesse. Disse opgaver kan omfatte følelsesanalyse, besvarelse af spørgsmål, navngivne enheds anerkendelse , eller enhver anden NLP-applikation. Modellens parametre justeres for at optimere dens ydeevne til de særlige krav til den aktuelle opgave.
BERTs forenede arkitektur gør det muligt at tilpasse sig forskellige downstream-opgaver med minimale ændringer, hvilket gør det til et alsidigt og yderst effektivt værktøj i naturlig sprogforståelse og forarbejdning.
Hvordan virker BERT?
BERT er designet til at generere en sprogmodel, så kun indkodermekanismen bruges. Sekvensen af tokens føres til Transformer-encoderen. Disse tokens indlejres først i vektorer og behandles derefter i det neurale netværk. Outputtet er en sekvens af vektorer, der hver svarer til et inputtoken, der giver kontekstualiserede repræsentationer.
Når man træner sprogmodeller, er det en udfordring at definere et forudsigelsesmål. Mange modeller forudsiger det næste ord i en sekvens, som er en retningsbestemt tilgang og kan begrænse kontekstlæring. BERT løser denne udfordring med to innovative træningsstrategier:
- Masked Language Model (MLM)
- Næste sætningsforudsigelse (NSP)
1. Masked Language Model (MLM)
I BERTs fortræningsproces maskeres en del af ordene i hver inputsekvens, og modellen trænes til at forudsige de oprindelige værdier af disse maskerede ord baseret på konteksten, som de omgivende ord giver.
Enkelt sagt,
- Maskeringsord: Før BERT lærer af sætninger, skjuler den nogle ord (ca. 15%) og erstatter dem med et særligt symbol, som f.eks. [MASK].
- Gætte skjulte ord: BERTs opgave er at finde ud af, hvad disse skjulte ord er ved at se på ordene omkring dem. Det er som et spil med at gætte, hvor nogle ord mangler, og BERT forsøger at udfylde de tomme felter.
- Sådan lærer BERT:
- BERT tilføjer et særligt lag oven på sit læringssystem for at foretage disse gæt. Den kontrollerer derefter, hvor tæt dens gæt er på de faktiske skjulte ord.
- Det gør det ved at konvertere sine gæt til sandsynligheder og sige, jeg tror, at dette ord er X, og jeg er så sikker på det.
- Særlig opmærksomhed på skjulte ord
- BERTs hovedfokus under træning er at få disse skjulte ord rigtigt. Den bekymrer sig mindre om at forudsige de ord, der ikke er skjulte.
- Det skyldes, at den virkelige udfordring er at finde ud af de manglende dele, og denne strategi hjælper BERT med at blive rigtig god til at forstå ordenes betydning og kontekst.
I tekniske termer,
- BERT tilføjer et klassifikationslag oven på outputtet fra encoderen. Dette lag er afgørende for at forudsige de maskerede ord.
- Outputvektorerne fra klassifikationslaget multipliceres med indlejringsmatricen, der transformerer dem til ordforrådsdimensionen. Dette trin hjælper med at tilpasse de forudsagte repræsentationer med ordforrådsrummet.
- Sandsynligheden for hvert ord i ordforrådet beregnes ved hjælp af SoftMax aktiveringsfunktion . Dette trin genererer en sandsynlighedsfordeling over hele ordforrådet for hver maskeret position.
- Tabsfunktionen, der bruges under træning, tager kun hensyn til forudsigelsen af de maskerede værdier. Modellen straffes for afvigelsen mellem dens forudsigelser og de faktiske værdier af de maskerede ord.
- Modellen konvergerer langsommere end retningsbestemte modeller. Dette skyldes, at BERT under træning kun er optaget af at forudsige de maskerede værdier og ignorere forudsigelsen af de ikke-maskerede ord. Den øgede kontekstbevidsthed opnået gennem denne strategi kompenserer for den langsommere konvergens.
2. Forudsigelse af næste sætning (NSP)
BERT forudsiger, om den anden sætning er forbundet med den første. Dette gøres ved at transformere outputtet af [CLS]-tokenet til en 2×1-formet vektor ved hjælp af et klassifikationslag, og derefter beregne sandsynligheden for, om den anden sætning følger den første ved hjælp af SoftMax.
- I træningsprocessen lærer BERT at forstå forholdet mellem sætningspar og forudsige, om den anden sætning følger den første i det originale dokument.
- 50 % af inputparrene har anden sætning som den efterfølgende sætning i originaldokumentet, og de øvrige 50 % har en tilfældigt valgt sætning.
- For at hjælpe modellen med at skelne mellem forbundne og afbrudte sætningspar. Indtastningen behandles, inden modellen indtastes:
- Et [CLS]-token indsættes i begyndelsen af den første sætning, og et [SEP]-token tilføjes i slutningen af hver sætning.
- En indlejret sætning, der angiver sætning A eller sætning B, føjes til hver token.
- En positionel indlejring angiver placeringen af hvert token i sekvensen.
- BERT forudsiger, om den anden sætning er forbundet med den første. Dette gøres ved at transformere outputtet af [CLS]-tokenet til en 2×1-formet vektor ved hjælp af et klassifikationslag, og derefter beregne sandsynligheden for, om den anden sætning følger den første ved hjælp af SoftMax.
Under træningen af BERT-modellen trænes Masked LM og Next Sentence Prediction sammen. Modellen sigter mod at minimere den kombinerede tabsfunktion af Masked LM og Next Sentence Prediction, hvilket fører til en robust sprogmodel med forbedrede evner til at forstå kontekst i sætninger og relationer mellem sætninger.
Hvorfor træne Masked LM og Next Sentence Prediction sammen?
Masked LM hjælper BERT med at forstå sammenhængen i en sætning og Forudsigelse af næste sætning hjælper BERT med at forstå sammenhængen eller forholdet mellem sætningspar. Derfor sikrer træning af begge strategier sammen, at BERT lærer en bred og omfattende forståelse af sproget, der fanger både detaljer i sætninger og flowet mellem sætninger.
BERT arkitekturer
Arkitekturen af BERT er en flerlags tovejs transformatorkoder, som er ret lig transformatormodellen. En transformerarkitektur er et encoder-decoder-netværk, der bruger selvopmærksomhed på encodersiden og opmærksomhed på dekodersiden.
- BERTGRUNDLAGhar 1 2 lag i Encoder-stakken mens BERTSTORhar 24 lag i Encoder-stakken . Disse er mere end Transformer-arkitekturen beskrevet i det originale papir ( 6 encoder lag ).
- BERT-arkitekturer (BASE og LARGE) har også større feedforward-netværk (henholdsvis 768 og 1024 skjulte enheder), og flere opmærksomhedshoveder (henholdsvis 12 og 16) end Transformer-arkitekturen foreslået i det originale papir. Det indeholder 512 skjulte enheder og 8 opmærksomhedshoveder .
- BERTGRUNDLAGindeholder 110M parametre, mens BERTSTORhar 340M parametre.

BERT BASE og BERT LARGE arkitektur.
Denne model tager CLS token som input først, så efterfølges det af en sekvens af ord som input. Her er CLS et klassifikationstoken. Det sender derefter input til ovenstående lag. Hvert lag gælder selvopmærksomhed og sender resultatet gennem et feedforward-netværk, hvorefter det videregives til den næste encoder. Modellen udsender en vektor af skjult størrelse ( 768 for BERT BASE). Hvis vi ønsker at udlæse en klassifikator fra denne model, kan vi tage output, der svarer til CLS-tokenet.
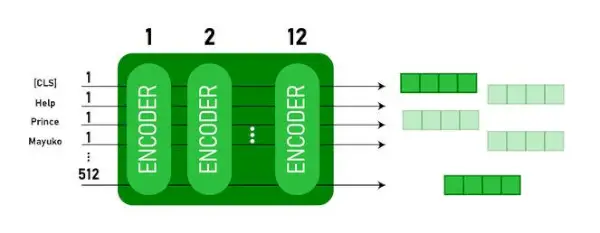
BERT output som indlejringer
Nu kan denne trænede vektor bruges til at udføre en række opgaver såsom klassificering, oversættelse osv. For eksempel opnår papiret fantastiske resultater blot ved at bruge et enkelt lag Neuralt netværk på BERT-modellen i klassifikationsopgaven.
Hvordan bruger man BERT-modellen i NLP?
BERT kan bruges til forskellige naturlige sprogbehandlingsopgaver (NLP), såsom:
1. Klassifikationsopgave
- BERT kan bruges til klassificeringsopgaver som følelsesanalyse , målet er at klassificere teksten i forskellige kategorier (positiv/negativ/neutral), BERT kan bruges ved at tilføje et klassifikationslag på toppen af Transformer-outputtet for [CLS]-tokenet.
- [CLS]-tokenet repræsenterer den aggregerede information fra hele inputsekvensen. Denne samlede repræsentation kan derefter bruges som input til et klassifikationslag til at lave forudsigelser for den specifikke opgave.
2. Besvarelse af spørgsmål
- I spørgsmålsbesvarelsesopgaver, hvor modellen skal lokalisere og markere svaret inden for en given tekstsekvens, kan BERT trænes til dette formål.
- BERT er trænet til at besvare spørgsmål ved at lære yderligere to vektorer, der markerer begyndelsen og slutningen af svaret. Under træningen forsynes modellen med spørgsmål og tilsvarende passager, og den lærer at forudsige besvarelsens start- og slutposition inden for passagen.
3. Navngivet enhedsgenkendelse (NER)
- BERT kan bruges til NER, hvor målet er at identificere og klassificere enheder (f.eks. Person, Organisation, Dato) i en tekstsekvens.
- En BERT-baseret NER-model trænes ved at tage outputvektoren for hver token fra transformeren og føre den ind i et klassifikationslag. Laget forudsiger den navngivne enhedslabel for hvert token, hvilket angiver den type enhed, det repræsenterer.
Hvordan tokenisere og kode tekst ved hjælp af BERT?
For at tokenisere og kode tekst ved hjælp af BERT, vil vi bruge 'transformer'-biblioteket i Python.
Kommando til at installere transformere:
!pip install transformers>
- Vi vil indlæse den fortrænede BERT-tokenize med et ordforråd med kasse ved hjælp af BertTokenizer.from_pretrained(bert-base-cased) .
- tokenizer.encode(tekst) tokeniserer inputteksten og konverterer den til en sekvens af token-id'er.
- print (token-id'er:, kodning) udskriver de token-id'er, der er opnået efter kodning.
- tokenizer.convert_ids_to_tokens(encoding) konverterer token-id'erne tilbage til deres tilsvarende tokens.
- print (Tokens:, tokens) udskriver de tokens, der er opnået efter konvertering af token-id'erne
Python3
from> transformers>import> BertTokenizer> # Load pre-trained BERT tokenizer> tokenizer>=> BertTokenizer.from_pretrained(>'bert-base-cased'>)> # Input text> text>=> 'ChatGPT is a language model developed by OpenAI, based on the GPT (Generative Pre-trained Transformer) architecture. '> # Tokenize and encode the text> encoding>=> tokenizer.encode(text)> # Print the token IDs> print>(>'Token IDs:'>, encoding)> # Convert token IDs back to tokens> tokens>=> tokenizer.convert_ids_to_tokens(encoding)> # Print the corresponding tokens> print>(>'Tokens:'>, tokens)> |
>
>
Produktion:
Token IDs: [101, 24705, 1204, 17095, 1942, 1110, 170, 1846, 2235, 1872, 1118, 3353, 1592, 2240, 117, 1359, 1113, 1103, 15175, 1942, 113, 9066, 15306, 11689, 118, 3972, 13809, 23763, 114, 4220, 119, 102] Tokens: ['[CLS]', 'Cha', '##t', '##GP', '##T', 'is', 'a', 'language', 'model', 'developed', 'by', 'Open', '##A', '##I', ',', 'based', 'on', 'the', 'GP', '##T', '(', 'Gene', '##rative', 'Pre', '-', 'trained', 'Trans', '##former', ')', 'architecture', '.', '[SEP]']> Det tokenizer.encode metode tilføjer det særlige [CLS] – klassifikation og [SEP] – separator tokens i begyndelsen og slutningen af den kodede sekvens.
Anvendelse af BERT
BERT bruges til:
- Tekstrepræsentation: BERT bruges til at generere ordindlejringer eller repræsentation for ord i en sætning.
- Anerkendelse af navngivet enhed (NER) : BERT kan finjusteres til navngivne enhedsgenkendelsesopgaver, hvor målet er at identificere entiteter såsom navne på personer, organisationer, lokationer osv. i en given tekst.
- Tekstklassificering: BERT bruges i vid udstrækning til tekstklassificeringsopgaver, herunder følelsesanalyse, spam-detektion og emnekategorisering. Det har demonstreret fremragende præstationer til at forstå og klassificere konteksten af tekstdata.
- Spørgsmålsbesvarelsessystemer: BERT er blevet anvendt på systemer til besvarelse af spørgsmål, hvor modellen trænes til at forstå konteksten af et spørgsmål og give relevante svar. Dette er især nyttigt til opgaver som læseforståelse.
- Maskinoversættelse: BERTs kontekstuelle indlejringer kan udnyttes til at forbedre maskinoversættelsessystemer. Modellen fanger sprogets nuancer, der er afgørende for nøjagtig oversættelse.
- Tekstopsummering: BERT kan bruges til abstrakt tekstresumé, hvor modellen genererer kortfattede og meningsfulde opsummeringer af længere tekster ved at forstå konteksten og semantikken.
- Samtale AI: BERT er beskæftiget med at bygge konversations-AI-systemer, såsom chatbots, virtuelle assistenter og dialogsystemer. Dens evne til at forstå konteksten gør den effektiv til at forstå og generere naturlige sprogresponser.
- Semantisk lighed: BERT-indlejringer kan bruges til at måle semantisk lighed mellem sætninger eller dokumenter. Dette er værdifuldt i opgaver som duplikatdetektion, parafrase-identifikation og informationssøgning.
BERT vs GPT
Forskellen mellem BERT og GPT er som følger:
| BERT | GPT | |
|---|---|---|
| Arkitektur | BERT er designet til tovejsrepræsentationslæring. Den bruger et maskeret sprogmodelmål, hvor det forudsiger manglende ord i en sætning baseret på både venstre og højre kontekst. | GPT er på den anden side designet til generativ sprogmodellering. Den forudsiger det næste ord i en sætning givet den foregående kontekst, ved at bruge en ensrettet autoregressiv tilgang. |
| Mål før træning | BERT er fortrænet ved hjælp af en maskeret sprogmodelmålsætning og forudsigelse af næste sætning. Det fokuserer på at fange tovejskontekst og forstå forhold mellem ord i en sætning. | GPT er fortrænet til at forudsige det næste ord i en sætning, hvilket tilskynder modellen til at lære en sammenhængende repræsentation af sprog og generere kontekstuelt relevante sekvenser. |
| Kontekstforståelse | BERT er effektiv til opgaver, der kræver en dyb forståelse af kontekst og relationer i en sætning, såsom tekstklassificering, navngivne enhedsgenkendelse og besvarelse af spørgsmål. | GPT er stærk til at generere sammenhængende og kontekstuelt relevant tekst. Det bruges ofte i kreative opgaver, dialogsystemer og opgaver, der kræver generering af naturlige sprogsekvenser. |
| Opgavetyper og Use Cases
| Bruges almindeligvis i opgaver som tekstklassificering, navngivet enhedsgenkendelse, sentimentanalyse og besvarelse af spørgsmål. | Anvendes til opgaver som tekstgenerering, dialogsystemer, opsummering og kreativ skrivning. |
| Finjustering vs Få-Shot Learning | BERT er ofte finjusteret på specifikke downstream-opgaver med mærkede data for at tilpasse sine forudtrænede repræsentationer til den aktuelle opgave. | GPT er designet til at udføre få-skuds læring, hvor det kan generaliseres til nye opgaver med minimale opgavespecifikke træningsdata. |
Tjek også:
- Følelsesklassificering ved hjælp af BERT
- Hvordan genererer man Word Embedding ved hjælp af BERT?
- BART-model for tekst autofuldførelse i NLP
- Toksisk kommentarklassificering ved brug af BERT
- Forudsigelse af næste sætning ved hjælp af BERT
Ofte stillede spørgsmål (FAQ)
Q. Hvad bruges BERT til?
BERT bruges til at udføre NLP-opgaver som tekstrepræsentation, navngivne enhedsgenkendelse, tekstklassificering, Q&A-systemer, maskinoversættelse, tekstresumé og mere.
Q. Hvad er fordelene ved BERT-modellen?
BERT-sprogmodellen skiller sig ud på grund af dens omfattende fortræning i flere sprog, der tilbyder en bred sproglig dækning sammenlignet med andre modeller. Dette gør BERT særligt fordelagtigt for ikke-engelsk-baserede projekter, da det giver robuste kontekstuelle repræsentationer og semantisk forståelse på tværs af en bred vifte af sprog, hvilket øger dens alsidighed i flersprogede applikationer.
Q. Hvordan virker BERT til sentimentanalyse?
BERT udmærker sig i sentimentanalyse ved at udnytte sin tovejsrepræsentationslæring til at fange kontekstuelle nuancer, semantiske betydninger og syntaktiske strukturer i en given tekst. Dette gør det muligt for BERT at forstå følelsen udtrykt i en sætning ved at overveje forholdet mellem ord, hvilket resulterer i yderst effektive sentimentanalyseresultater.
xor c++
Q. Er Google baseret på BERT?
BERT og RankBrain er komponenter i Googles søgealgoritme til at behandle forespørgsler og websiders indhold for at opnå bedre forståelse for at forbedre søgeresultaterne.