Følgende arkitektur forklarer strømmen af indsendelse af forespørgsler til Hive.
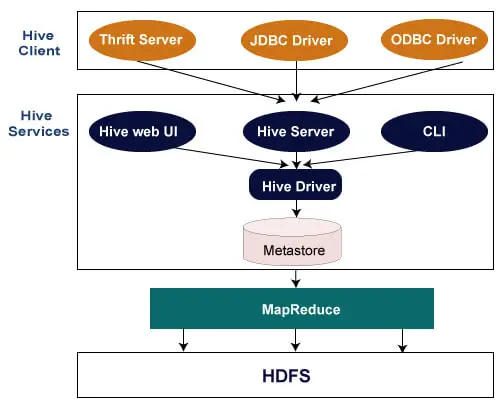
Hive klient
Hive giver mulighed for at skrive applikationer på forskellige sprog, herunder Java, Python og C++. Det understøtter forskellige typer klienter såsom: -
- Thrift Server - Det er en tværsproglig tjenesteudbyderplatform, der betjener anmodningen fra alle de programmeringssprog, der understøtter Thrift.
- JDBC Driver - Den bruges til at etablere en forbindelse mellem hive og Java-applikationer. JDBC-driveren er til stede i klassen org.apache.hadoop.hive.jdbc.HiveDriver.
- ODBC Driver - Det tillader de applikationer, der understøtter ODBC-protokollen, at oprette forbindelse til Hive.
Hive Services
Følgende er de tjenester, der leveres af Hive:-
- Hive CLI - Hive CLI (Command Line Interface) er en shell, hvor vi kan udføre Hive-forespørgsler og -kommandoer.
- Hive Web Brugergrænseflade - Hive Web UI er blot et alternativ til Hive CLI. Det giver en webbaseret GUI til at udføre Hive-forespørgsler og -kommandoer.
- Hive MetaStore - Det er et centralt lager, der gemmer alle strukturoplysningerne for forskellige tabeller og partitioner på lageret. Det inkluderer også metadata for kolonne og dens typeinformation, serializers og deserializers, som bruges til at læse og skrive data og de tilsvarende HDFS-filer, hvor dataene er gemt.
- Hive Server - Den omtales som Apache Thrift Server. Den accepterer anmodningen fra forskellige klienter og giver den til Hive Driver.
- Hive Driver - Den modtager forespørgsler fra forskellige kilder som web UI, CLI, Thrift og JDBC/ODBC driver. Det overfører forespørgslerne til compileren.
- Hive Compiler - Formålet med compileren er at parse forespørgslen og udføre semantisk analyse på de forskellige forespørgselsblokke og udtryk. Det konverterer HiveQL-udsagn til MapReduce-job.
- Hive Execution Engine - Optimizer genererer den logiske plan i form af DAG af map-reduce-opgaver og HDFS-opgaver. I sidste ende udfører eksekveringsmotoren de indkommende opgaver i rækkefølgen efter deres afhængigheder.