Neurale netværk er beregningsmodeller, der efterligner den menneskelige hjernes komplekse funktioner. De neurale netværk består af indbyrdes forbundne noder eller neuroner, der behandler og lærer af data, hvilket muliggør opgaver såsom mønstergenkendelse og beslutningstagning i maskinlæring. Artiklen udforsker mere om neurale netværk, deres virkemåde, arkitektur og mere.
Indholdsfortegnelse
- Udvikling af neurale netværk
- Hvad er neurale netværk?
- Hvordan fungerer neurale netværk?
- Læring af et neuralt netværk
- Typer af neurale netværk
- Enkel implementering af et neuralt netværk
Udvikling af neurale netværk
Siden 1940'erne har der været en række bemærkelsesværdige fremskridt inden for neurale netværk:
- 1940'erne-1950'erne: Tidlige koncepter
Neurale netværk begyndte med introduktionen af den første matematiske model af kunstige neuroner af McCulloch og Pitts. Men beregningsmæssige begrænsninger gjorde fremskridt vanskeligt.
- 1960'erne-1970'erne: Perceptroner
Denne æra er defineret af Rosenblatts arbejde med perceptroner. Perceptroner er enkeltlagsnetværk, hvis anvendelighed var begrænset til problemer, der kunne løses lineært separat.
- 1980'erne: Backpropagation og Connectionism
Flerlags netværk træning blev muliggjort af Rumelhart, Hinton og Williams' opfindelse af tilbageformeringsmetoden. Med sin vægt på læring gennem indbyrdes forbundne knudepunkter, fik forbindelseisme appel.
- 1990'erne: Boom and Winter
Med applikationer inden for billedidentifikation, økonomi og andre områder oplevede neurale netværk et boom. Neurale netværksforskning oplevede dog en vinter på grund af ublu beregningsomkostninger og oppustede forventninger.
- 2000'erne: Genopblomstring og dyb læring
Større datasæt, innovative strukturer og forbedret behandlingsevne ansporede et comeback. Dyb læring har vist fantastisk effektivitet i en række discipliner ved at bruge adskillige lag.
- 2010'erne-nu: Deep Learning Dominance
Konvolutionelle neurale netværk (CNN'er) og tilbagevendende neurale netværk (RNN'er), to dybe læringsarkitekturer, dominerede maskinlæring. Deres magt blev demonstreret af innovationer inden for spil, billedgenkendelse og naturlig sprogbehandling.
Hvad er neurale netværk?
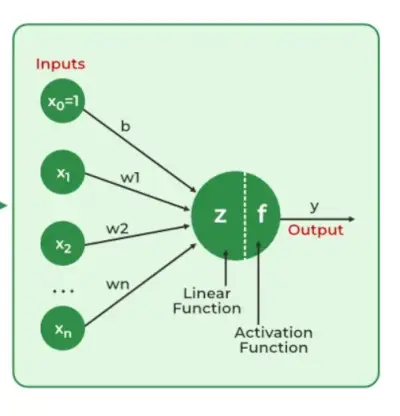
Neurale netværk udtrække identificerende funktioner fra data, der mangler forudprogrammeret forståelse. Netværkskomponenter omfatter neuroner, forbindelser, vægte, skævheder, udbredelsesfunktioner og en indlæringsregel. Neuroner modtager input, styret af tærskler og aktiveringsfunktioner. Forbindelser involverer vægte og skævheder, der regulerer informationsoverførsel. Indlæring, justering af vægte og skævheder sker i tre faser: inputberegning, outputgenerering og iterativ forfining, der forbedrer netværkets færdigheder i forskellige opgaver.
Disse omfatter:
- Det neurale netværk simuleres af et nyt miljø.
- Derefter ændres de frie parametre for det neurale netværk som et resultat af denne simulering.
- Det neurale netværk reagerer derefter på en ny måde på miljøet på grund af ændringerne i dets frie parametre.
Betydningen af neurale netværk
Neurale netværks evne til at identificere mønstre, løse indviklede gåder og tilpasse sig skiftende omgivelser er afgørende. Deres evne til at lære af data har vidtrækkende effekter, lige fra revolutionerende teknologi som naturlig sprogbehandling og selvkørende biler til at automatisere beslutningsprocesser og øge effektiviteten i adskillige industrier. Udviklingen af kunstig intelligens er i høj grad afhængig af neurale netværk, som også driver innovation og påvirker teknologiens retning.
Hvordan fungerer neurale netværk?
Lad os forstå med et eksempel på, hvordan et neuralt netværk fungerer:
Overvej et neuralt netværk til e-mail-klassificering. Inputlaget tager funktioner som e-mailindhold, afsenderoplysninger og emne. Disse input, ganget med justerede vægte, passerer gennem skjulte lag. Netværket lærer gennem træning at genkende mønstre, der indikerer, om en e-mail er spam eller ej. Outputlaget, med en binær aktiveringsfunktion, forudsiger, om e-mailen er spam (1) eller ej (0). Efterhånden som netværket iterativt forfiner sine vægte gennem tilbageudbredelse, bliver det dygtigt til at skelne mellem spam og legitime e-mails, og viser det praktiske ved neurale netværk i applikationer fra den virkelige verden som e-mailfiltrering.
Arbejde med et neuralt netværk
Neurale netværk er komplekse systemer, der efterligner nogle funktioner i den menneskelige hjernes funktion. Det er sammensat af et inputlag, et eller flere skjulte lag og et outputlag, der består af lag af kunstige neuroner, der er koblet. De to trin i den grundlæggende proces kaldes backpropagation og fremadrettet udbredelse .
chmod 755
Fremadrettet udbredelse
- Input lag: Hver funktion i inputlaget er repræsenteret af en node på netværket, som modtager inputdata.
- Vægte og forbindelser: Vægten af hver neuronal forbindelse indikerer, hvor stærk forbindelsen er. Under hele træningen ændres disse vægte.
- Skjulte lag: Hvert skjult lag neuron behandler input ved at gange dem med vægte, lægge dem sammen og derefter sende dem gennem en aktiveringsfunktion. Ved at gøre dette introduceres ikke-linearitet, hvilket gør netværket i stand til at genkende indviklede mønstre.
- Produktion: Det endelige resultat frembringes ved at gentage processen, indtil outputlaget er nået.
Tilbageformning
- Tabsberegning: Netværkets output evalueres i forhold til de reelle målværdier, og en tabsfunktion bruges til at beregne forskellen. For et regressionsproblem er Mean Squared Fejl (MSE) bruges almindeligvis som omkostningsfunktionen.
Tabsfunktion:
- Gradientnedstigning: Gradientnedstigning bruges derefter af netværket til at reducere tabet. For at mindske unøjagtigheden ændres vægte baseret på derivatet af tabet med hensyn til hver vægt.
- Justering af vægte: Vægtene justeres ved hver forbindelse ved at anvende denne iterative proces, eller tilbageudbredelse , baglæns på tværs af netværket.
- Uddannelse: Under træning med forskellige dataeksempler udføres hele processen med fremadrettet udbredelse, tabsberegning og tilbageudbredelse iterativt, hvilket gør netværket i stand til at tilpasse og lære mønstre fra dataene.
- Aktiveringsfunktioner: Model ikke-linearitet introduceres af aktiveringsfunktioner som ensrettet lineær enhed (ReLU) timer sigmoid . Deres beslutning om, hvorvidt de skal affyre en neuron, er baseret på hele det vægtede input.

Læring af et neuralt netværk
1. Læring med superviseret læring
I overvåget læring , er det neurale netværk styret af en lærer, der har adgang til begge input-output-par. Netværket skaber output baseret på input uden at tage hensyn til omgivelserne. Ved at sammenligne disse output med de lærerkendte ønskede output, genereres et fejlsignal. For at reducere fejl ændres netværkets parametre iterativt og stopper, når ydeevnen er på et acceptabelt niveau.
2. Læring med uovervåget læring
Tilsvarende outputvariable er fraværende i uovervåget læring . Dens hovedmål er at forstå indgående datas (X) underliggende struktur. Ingen instruktør er til stede for at give råd. Modellering af datamønstre og relationer er det tilsigtede resultat i stedet. Ord som regression og klassifikation er relateret til superviseret læring, hvorimod uovervåget læring er forbundet med clustering og association.
3. Læring med forstærkningslæring
Gennem interaktion med omgivelserne og feedback i form af belønninger eller straf får netværket viden. At finde en politik eller strategi, der optimerer kumulative belønninger over tid, er målet for netværket. Denne type bruges ofte i spil og beslutningstagningsapplikationer.
Typer af neurale netværk
Der er syv typer af neurale netværk, der kan bruges.
- Feedforward-netværk: EN feedforward neurale netværk er en simpel kunstig neural netværksarkitektur, hvor data bevæger sig fra input til output i en enkelt retning. Den har input-, skjulte- og outputlag; feedback loops er fraværende. Dens ligefremme arkitektur gør den velegnet til en række applikationer, såsom regression og mønstergenkendelse.
- Multilayer Perceptron (MLP): MLP er en type feedforward neuralt netværk med tre eller flere lag, inklusive et inputlag, et eller flere skjulte lag og et outputlag. Den bruger ikke-lineære aktiveringsfunktioner.
- Convolutional Neural Network (CNN): EN Konvolutionelt neuralt netværk (CNN) er et specialiseret kunstigt neuralt netværk designet til billedbehandling. Den anvender foldningslag til automatisk at lære hierarkiske funktioner fra inputbilleder, hvilket muliggør effektiv billedgenkendelse og klassificering. CNN'er har revolutioneret computersyn og er afgørende i opgaver som objektgenkendelse og billedanalyse.
- Gentagende neuralt netværk (RNN): En kunstig neural netværkstype beregnet til sekventiel databehandling kaldes en Tilbagevendende neuralt netværk (RNN). Det er velegnet til applikationer, hvor kontekstuelle afhængigheder er kritiske, såsom forudsigelse af tidsserier og naturlig sprogbehandling, da den gør brug af feedback-loops, som gør det muligt for information at overleve i netværket.
- Langtidshukommelse (LSTM): LSTM er en type RNN, der er designet til at overvinde problemet med forsvindende gradient ved træning af RNN'er. Den bruger hukommelsesceller og porte til selektivt at læse, skrive og slette information.
Enkel implementering af et neuralt netværk
Python3
import> numpy as np> # array of any amount of numbers. n = m> X>=> np.array([[>1>,>2>,>3>],> >[>3>,>4>,>1>],> >[>2>,>5>,>3>]])> # multiplication> y>=> np.array([[.>5>, .>3>, .>2>]])> # transpose of y> y>=> y.T> # sigma value> sigm>=> 2> # find the delta> delt>=> np.random.random((>3>,>3>))>-> 1> for> j>in> range>(>100>):> > ># find matrix 1. 100 layers.> >m1>=> (y>-> (>1>/>(>1> +> np.exp(>->(np.dot((>1>/>(>1> +> np.exp(> >->(np.dot(X, sigm))))), delt))))))>*>((>1>/>(> >1> +> np.exp(>->(np.dot((>1>/>(>1> +> np.exp(> >->(np.dot(X, sigm))))), delt)))))>*>(>1>->(>1>/>(> >1> +> np.exp(>->(np.dot((>1>/>(>1> +> np.exp(> >->(np.dot(X, sigm))))), delt)))))))> ># find matrix 2> >m2>=> m1.dot(delt.T)>*> ((>1>/>(>1> +> np.exp(>->(np.dot(X, sigm)))))> >*> (>1>->(>1>/>(>1> +> np.exp(>->(np.dot(X, sigm)))))))> ># find delta> >delt>=> delt>+> (>1>/>(>1> +> np.exp(>->(np.dot(X, sigm))))).T.dot(m1)> ># find sigma> >sigm>=> sigm>+> (X.T.dot(m2))> # print output from the matrix> print>(>1>/>(>1> +> np.exp(>->(np.dot(X, sigm)))))> |
>
>
Produktion:
[[0.99999325 0.99999375 0.99999352] [0.99999988 0.99999989 0.99999988] [1. 1. 1. ]]>
Fordele ved neurale netværk
Neurale netværk er meget udbredt i mange forskellige applikationer på grund af deres mange fordele:
- Tilpasningsevne: Neurale netværk er nyttige til aktiviteter, hvor forbindelsen mellem input og output er kompleks eller ikke veldefineret, fordi de kan tilpasse sig nye situationer og lære af data.
- Mønster genkendelse: Deres færdigheder i mønstergenkendelse gør dem effektive i opgaver som lyd- og billedidentifikation, naturlig sprogbehandling og andre indviklede datamønstre.
- Parallel behandling: Fordi neurale netværk er i stand til parallel behandling af natur, kan de behandle adskillige job på én gang, hvilket fremskynder og forbedrer effektiviteten af beregninger.
- Ikke-linearitet: Neurale netværk er i stand til at modellere og forstå komplicerede forhold i data i kraft af de ikke-lineære aktiveringsfunktioner, der findes i neuroner, som overvinder ulemperne ved lineære modeller.
Ulemper ved neurale netværk
Neurale netværk er, selvom de er kraftfulde, ikke uden ulemper og vanskeligheder:
- Beregningsintensitet: Træning i store neurale netværk kan være en besværlig og beregningskrævende proces, der kræver meget computerkraft.
- Sort boks natur: Som black box-modeller udgør neurale netværk et problem i vigtige applikationer, da det er svært at forstå, hvordan de træffer beslutninger.
- Overpasning: Overfitting er et fænomen, hvor neurale netværk forpligter træningsmateriale til hukommelsen i stedet for at identificere mønstre i dataene. Selvom regulariseringsmetoder hjælper med at afhjælpe dette, eksisterer problemet stadig.
- Behov for store datasæt: For effektiv træning har neurale netværk ofte brug for store, mærkede datasæt; ellers kan deres præstation lide af ufuldstændige eller skæve data.
Ofte stillede spørgsmål (ofte stillede spørgsmål)
1. Hvad er et neuralt netværk?
Et neuralt netværk er et kunstigt system lavet af indbyrdes forbundne noder (neuroner), der behandler information, modelleret efter strukturen af den menneskelige hjerne. Det bruges i maskinlæringsjob, hvor mønstre udvindes fra data.
2. Hvordan fungerer et neuralt netværk?
Lag af forbundne neuroner behandler data i neurale netværk. Netværket behandler inputdata, ændrer vægte under træning og producerer et output afhængigt af mønstre, som det har opdaget.
3. Hvad er de almindelige typer af neurale netværksarkitekturer?
Feedforward neurale netværk, recurrent neurale netværk (RNN'er), convolutional neurale netværk (CNN'er) og langtidskorttidshukommelsesnetværk (LSTM'er) er eksempler på almindelige arkitekturer, der hver især er designet til en bestemt opgave.
4. Hvad er forskellen mellem superviseret og uovervåget læring i neurale netværk?
I overvåget læring bruges mærkede data til at træne et neuralt netværk, så det kan lære at kortlægge input til matchende output. Uovervåget læring arbejder med umærkede data og leder efter strukturer eller mønstre i dataene .
5. Hvordan håndterer neurale netværk sekventielle data?
Feedback-sløjferne, som tilbagevendende neurale netværk (RNN'er) inkorporerer, giver dem mulighed for at behandle sekventielle data og over tid fange afhængigheder og kontekst.