EN Convolutional Neural Network (CNN) er en type Deep Learning neural netværksarkitektur, der almindeligvis bruges i Computer Vision. Computersyn er et felt af kunstig intelligens, der gør det muligt for en computer at forstå og fortolke billedet eller visuelle data.
Når det kommer til Machine Learning, Kunstige neurale netværk præstere rigtig godt. Neurale netværk bruges i forskellige datasæt som billeder, lyd og tekst. Forskellige typer af neurale netværk bruges til forskellige formål, for eksempel til at forudsige rækkefølgen af ord, vi bruger Tilbagevendende neurale netværk mere præcist en LSTM , på samme måde til billedklassificering bruger vi Convolution Neurale netværk. I denne blog skal vi bygge en grundlæggende byggesten til CNN.
I et almindeligt neuralt netværk er der tre typer lag:
struktur i datastruktur
- Input lag: Det er det lag, vi giver input til vores model i. Antallet af neuroner i dette lag er lig med det samlede antal funktioner i vores data (antal pixels i tilfælde af et billede).
- Skjult lag: Inputtet fra inputlaget føres derefter ind i det skjulte lag. Der kan være mange skjulte lag afhængigt af vores model og datastørrelse. Hvert skjult lag kan have forskelligt antal neuroner, som generelt er større end antallet af funktioner. Outputtet fra hvert lag beregnes ved matrixmultiplikation af outputtet fra det foregående lag med indlæselige vægte af dette lag og derefter ved tilføjelse af indlærbare skævheder efterfulgt af aktiveringsfunktion, som gør netværket ikke-lineært.
- Outputlag: Outputtet fra det skjulte lag føres derefter ind i en logistisk funktion som sigmoid eller softmax, som konverterer output fra hver klasse til sandsynlighedsscore for hver klasse.
Dataene føres ind i modellen og output fra hvert lag opnås fra ovenstående trin kaldes feedforward , beregner vi så fejlen ved hjælp af en fejlfunktion, nogle almindelige fejlfunktioner er krydsentropi, kvadrattabsfejl osv. Fejlfunktionen måler hvor godt netværket præsterer. Derefter propagerer vi tilbage i modellen ved at beregne derivaterne. Dette trin kaldes Convolutional Neural Network (CNN) er den udvidede version af kunstige neurale netværk (ANN) som overvejende bruges til at udtrække funktionen fra det gitterlignende matrixdatasæt. For eksempel visuelle datasæt som billeder eller videoer, hvor datamønstre spiller en omfattende rolle.
CNN arkitektur
Convolutional Neural Network består af flere lag som inputlaget, Convolutional lag, Pooling lag og fuldt forbundne lag.

Simpel CNN-arkitektur
Konvolutionslaget anvender filtre på inputbilledet for at udtrække funktioner, Pooling-laget nedsampler billedet for at reducere beregningen, og det fuldt forbundne lag foretager den endelige forudsigelse. Netværket lærer de optimale filtre gennem backpropagation og gradient descent.
Hvordan Convolutional Layers fungerer
Convolution Neural Networks eller covnets er neurale netværk, der deler deres parametre. Forestil dig, at du har et billede. Det kan repræsenteres som en kuboid med sin længde, bredde (billedets dimension) og højde (dvs. kanalen, da billeder generelt har røde, grønne og blå kanaler).
Forestil dig nu at tage en lille lap af dette billede og køre et lille neuralt netværk, kaldet et filter eller kerne på det, med f.eks. K output og repræsentere dem lodret. Skub nu det neurale netværk hen over hele billedet, som et resultat, vil vi få et andet billede med forskellige bredder, højder og dybder. I stedet for kun R-, G- og B-kanaler har vi nu flere kanaler, men mindre bredde og højde. Denne operation kaldes Konvolution . Hvis patchstørrelsen er den samme som billedet, vil det være et almindeligt neuralt netværk. På grund af dette lille plaster har vi færre vægte.
Billedkilde: Deep Learning Udacity
Lad os nu tale om lidt matematik, der er involveret i hele foldningsprocessen.
- Konvolutionslag består af et sæt lærbare filtre (eller kerner) med små bredder og højder og samme dybde som inputvolumen (3 hvis inputlaget er billedinput).
- For eksempel, hvis vi skal køre foldning på et billede med dimensionerne 34x34x3. Den mulige størrelse af filtre kan være axax3, hvor 'a' kan være noget som 3, 5 eller 7, men mindre i forhold til billeddimensionen.
- Under den fremadgående passage glider vi hvert filter hen over hele inputvolumen trin for trin, hvor hvert trin kaldes skridt (som kan have en værdi på 2, 3 eller endda 4 for højdimensionelle billeder) og beregne prikproduktet mellem kernevægtene og patchen ud fra inputvolumen.
- Når vi skubber vores filtre, får vi et 2-D output for hvert filter, og vi stabler dem sammen som et resultat, vi får outputvolumen med en dybde svarende til antallet af filtre. Netværket lærer alle filtrene.
Lag, der bruges til at bygge ConvNets
En komplet Convolution Neural Networks-arkitektur er også kendt som covnets. En covnet er en sekvens af lag, og hvert lag transformerer et volumen til et andet gennem en differentierbar funktion.
Typer af lag: datasæt
Lad os tage et eksempel ved at køre en kappe på et billede med dimension 32 x 32 x 3.
heltal til streng
- Input lag: Det er det lag, vi giver input til vores model i. I CNN vil input generelt være et billede eller en sekvens af billeder. Dette lag holder billedets rå input med bredde 32, højde 32 og dybde 3.
- Konvolutionelle lag: Dette er laget, som bruges til at udtrække funktionen fra inputdatasættet. Det anvender et sæt lærbare filtre kendt som kernerne på inputbillederne. Filtrene/kernerne er mindre matricer, normalt 2×2, 3×3 eller 5×5 form. den glider hen over inputbilleddataene og beregner prikproduktet mellem kernevægt og den tilsvarende inputbilledpatch. Outputtet af dette lag omtales som feature maps. Antag, at vi bruger i alt 12 filtre til dette lag, så får vi et outputvolumen på dimension 32 x 32 x 12.
- Aktiveringslag: Ved at tilføje en aktiveringsfunktion til outputtet fra det foregående lag tilføjer aktiveringslag netværket ikke-linearitet. den vil anvende en elementmæssig aktiveringsfunktion til outputtet af foldningslaget. Nogle almindelige aktiveringsfunktioner er Genoptag : max(0, x), Fisket , Utæt RELU osv. Volumen forbliver uændret, og outputvolumen vil derfor have dimensionerne 32 x 32 x 12.
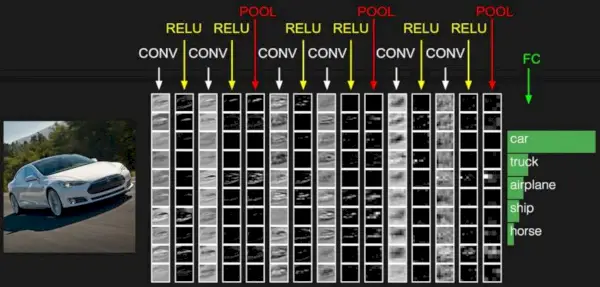
- Pooling lag: Dette lag indsættes med jævne mellemrum i kapperne, og dets hovedfunktion er at reducere størrelsen af volumen, hvilket gør, at beregningen hurtigt reducerer hukommelsen og forhindrer også overfitting. To almindelige typer af pooling lag er max pooling og gennemsnitlig sammenlægning . Hvis vi bruger en max pool med 2 x 2 filtre og skridt 2, vil det resulterende volumen være af dimensionen 16x16x12.
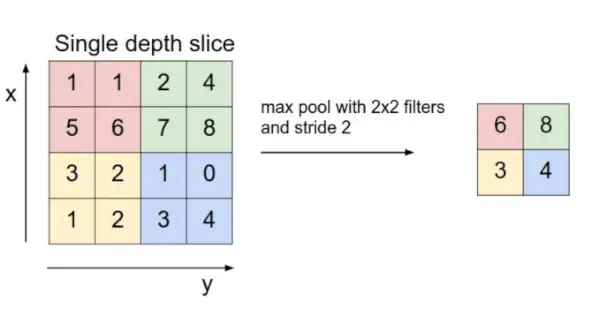
Billedkilde: cs231n.stanford.edu
- Udfladning: De resulterende feature maps er fladtrykt til en en-dimensionel vektor efter foldning og pooling lag, så de kan overføres til et fuldstændigt forbundet lag til kategorisering eller regression.
- Fuldt forbundne lag: Den tager input fra det forrige lag og beregner den endelige klassifikations- eller regressionsopgave.
Billedkilde: cs231n.stanford.edu
- Outputlag: Outputtet fra de fuldt forbundne lag føres derefter ind i en logistisk funktion til klassificeringsopgaver som sigmoid eller softmax, som konverterer output fra hver klasse til sandsynlighedsscore for hver klasse.
Eksempel:
Lad os overveje et billede og anvende foldningslaget, aktiveringslaget og poolingslagets operation for at udtrække den indvendige funktion.
css-tekstjustering
Input billede:
Indtast billede
Trin:
- importere de nødvendige biblioteker
- indstille parameteren
- definere kernen
- Indlæs billedet og plot det.
- Omformater billedet
- Anvend foldningslagsoperation og plot outputbilledet.
- Anvend aktiveringslagsdrift og plot outputbilledet.
- Anvend pooling layer operation og plot outputbilledet.
Python3
# import the necessary libraries> import> numpy as np> import> tensorflow as tf> import> matplotlib.pyplot as plt> from> itertools>import> product> > # set the param> plt.rc(>'figure'>, autolayout>=>True>)> plt.rc(>'image'>, cmap>=>'magma'>)> > # define the kernel> kernel>=> tf.constant([[>->1>,>->1>,>->1>],> >[>->1>,>8>,>->1>],> >[>->1>,>->1>,>->1>],> >])> > # load the image> image>=> tf.io.read_file(>'Ganesh.webp'plain'>)> image>=> tf.io.decode_jpeg(image, channels>=>1>)> image>=> tf.image.resize(image, size>=>[>300>,>300>])> > # plot the image> img>=> tf.squeeze(image).numpy()> plt.figure(figsize>=>(>5>,>5>))> plt.imshow(img, cmap>=>'gray'>)> plt.axis(>'off'>)> plt.title(>'Original Gray Scale image'>)> plt.show();> > > # Reformat> image>=> tf.image.convert_image_dtype(image, dtype>=>tf.float32)> image>=> tf.expand_dims(image, axis>=>0>)> kernel>=> tf.reshape(kernel, [>*>kernel.shape,>1>,>1>])> kernel>=> tf.cast(kernel, dtype>=>tf.float32)> > # convolution layer> conv_fn>=> tf.nn.conv2d> > image_filter>=> conv_fn(> >input>=>image,> >filters>=>kernel,> >strides>=>1>,># or (1, 1)> >padding>=>'SAME'>,> )> > plt.figure(figsize>=>(>15>,>5>))> > # Plot the convolved image> plt.subplot(>1>,>3>,>1>)> > plt.imshow(> >tf.squeeze(image_filter)> )> plt.axis(>'off'>)> plt.title(>'Convolution'>)> > # activation layer> relu_fn>=> tf.nn.relu> # Image detection> image_detect>=> relu_fn(image_filter)> > plt.subplot(>1>,>3>,>2>)> plt.imshow(> ># Reformat for plotting> >tf.squeeze(image_detect)> )> > plt.axis(>'off'>)> plt.title(>'Activation'>)> > # Pooling layer> pool>=> tf.nn.pool> image_condense>=> pool(>input>=>image_detect,> >window_shape>=>(>2>,>2>),> >pooling_type>=>'MAX'>,> >strides>=>(>2>,>2>),> >padding>=>'SAME'>,> >)> > plt.subplot(>1>,>3>,>3>)> plt.imshow(tf.squeeze(image_condense))> plt.axis(>'off'>)> plt.title(>'Pooling'>)> plt.show()> |
>
afkorte og slette forskel
>
Produktion :

Originalt gråtonebillede
Produktion
Fordele ved Convolutional Neural Networks (CNN'er):
- God til at opdage mønstre og funktioner i billeder, videoer og lydsignaler.
- Robust til oversættelse, rotation og skaleringsinvarians.
- End-to-end træning, intet behov for manuel funktionsudtrækning.
- Kan håndtere store mængder data og opnå høj nøjagtighed.
Ulemper ved Convolutional Neural Networks (CNN'er):
- Beregningsmæssigt dyrt at træne og kræver meget hukommelse.
- Kan være tilbøjelig til overfitting, hvis der ikke bruges nok data eller korrekt regularisering.
- Kræver store mængder mærkede data.
- Fortolkbarheden er begrænset, det er svært at forstå, hvad netværket har lært.
Ofte stillede spørgsmål (FAQ)
1: Hvad er et Convolutional Neural Network (CNN)?
A Convolutional Neural Network (CNN) er en type deep learning neuralt netværk, der er velegnet til billed- og videoanalyse. CNN'er bruger en række foldnings- og poollag til at udtrække funktioner fra billeder og videoer og bruger derefter disse funktioner til at klassificere eller detektere objekter eller scener.
2: Hvordan fungerer CNN'er?
CNN'er fungerer ved at anvende en række foldning og poolingslag på et inputbillede eller en video. Konvolutionslag udtrækker funktioner fra inputtet ved at skubbe et lille filter eller kerne hen over billedet eller videoen og beregne prikproduktet mellem filteret og inputtet. Pooling-lag nedsampler derefter outputtet af foldningslagene for at reducere dimensionaliteten af dataene og gøre dem mere beregningseffektive.
sammenligne i java
3: Hvad er nogle almindelige aktiveringsfunktioner, der bruges i CNN'er?
Nogle almindelige aktiveringsfunktioner, der bruges i CNN'er, inkluderer:
- Rectified Linear Unit (ReLU): ReLU er en ikke-mættende aktiveringsfunktion, der er beregningseffektiv og nem at træne.
- Leaky Rectified Linear Unit (Leaky ReLU): Leaky ReLU er en variant af ReLU, der tillader en lille mængde negativ gradient at strømme gennem netværket. Dette kan være med til at forhindre, at netværket dør under træning.
- Parametric Rectified Linear Unit (PReLU): PReLU er en generalisering af Leaky ReLU, der gør det muligt at lære hældningen af den negative gradient.
4: Hvad er formålet med at bruge flere foldningslag i et CNN?
Brug af flere foldningslag i et CNN giver netværket mulighed for at lære mere og mere komplekse funktioner fra inputbilledet eller videoen. De første foldningslag lærer simple funktioner, såsom kanter og hjørner. De dybere foldningslag lærer mere komplekse funktioner, såsom former og objekter.
5: Hvad er nogle almindelige regulariseringsteknikker, der bruges i CNN'er?
Regulariseringsteknikker bruges til at forhindre CNN i at overfitte træningsdataene. Nogle almindelige regulariseringsteknikker, der bruges i CNN'er, inkluderer:
- Frafald: Frafald falder tilfældigt neuroner ud af netværket under træning. Dette tvinger netværket til at lære mere robuste funktioner, der ikke er afhængige af en enkelt neuron.
- L1-regularisering: L1-regularisering regulariserer den absolutte værdi af vægtene i netværket. Dette kan være med til at reducere antallet af vægte og gøre netværket mere effektivt.
- L2-regularisering: L2-regularisering regulariserer kvadratet af vægtene i netværket. Dette kan også være med til at reducere antallet af vægte og gøre netværket mere effektivt.
6: Hvad er forskellen mellem et foldningslag og et poolingslag?
Et foldningslag udtrækker funktioner fra et inputbillede eller en video, mens et poolinglag nedsampler outputtet fra foldningslagene. Konvolutionslag bruger en række filtre til at udtrække funktioner, mens poolinglag bruger en række forskellige teknikker til at nedsample dataene, såsom maksimal pooling og gennemsnitlig pooling.