I dag er data en af de vigtigste ting i forretningsverdenen, enhver virksomhed fanger sine kunders data for at forstå deres adfærd, i internettets verden vokser data som en vanvittig, så virksomheder har brug for mere avancerede databaseløsninger, hvorved de kan vedligeholde databasesystemerne, og når de har brug for data for at løse forretningsproblemer, kan de nemt få de data, de vil have, uden problemer. For at opfylde denne betingelse er der et krav om databaseskemaet på billedet.
Hvad er skema?
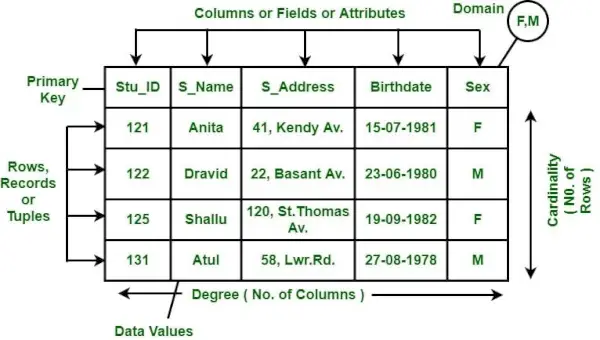
- Skelettet i databasen er skabt af attributterne, og dette skelet hedder Schema.
- Skema nævner de logiske begrænsninger som tabel, primær nøgle osv.
- Skemaet repræsenterer ikke datatypen for attributterne.
Oplysninger om en kunde
Kundeskema
Database skema
- Et databaseskema er en logisk repræsentation af data der viser, hvordan dataene i en database logisk skal lagres. Det viser, hvordan data er organiseret og forholdet mellem tabellerne.
- Databaseskema indeholder tabel, felt, visninger og relation mellem forskellige nøgler som f.eks primærnøgle , fremmed nøgle .
- Data gemmes i form af filer, som er ustrukturerede, hvilket gør det vanskeligt at få adgang til dataene. For at løse problemet er dataene organiseret på en struktureret måde ved hjælp af databaseskema.
- Databaseskema giver organiseringen af data og forholdet mellem de lagrede data.
- Databaseskema definerer et sæt retningslinjer, der styrer databasen, samt at det giver information om måden at få adgang til og ændre dataene på.
Typer af databaseskemaer
Der er 3 typer databaseskemaer:
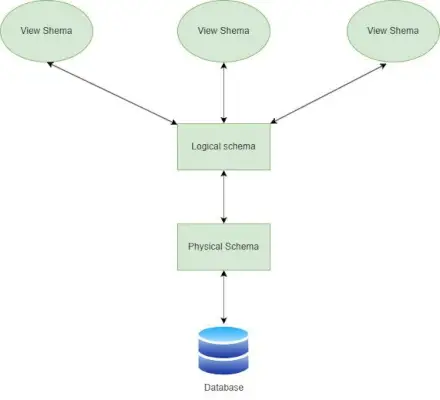
Fysisk databaseskema
- Et fysisk skema definerer, hvordan data eller information lagres fysisk i lagersystemerne i form af filer og indekser. Dette er den faktiske kode eller syntaks, der er nødvendig for at skabe strukturen af en database, vi kan sige, at når vi designer en database på et fysisk niveau, kaldes det fysisk skema.
- Databaseadministratoren vælger, hvor og hvordan dataene skal lagres i de forskellige lagerblokke.
Logisk databaseskema
- Et logisk databaseskema definerer alle de logiske begrænsninger, der skal anvendes på de lagrede data, og beskriver også tabeller, visninger, entitetsrelationer og integritetsbegrænsninger.
- Det logiske skema beskriver, hvordan data gemmes i form af tabeller, og hvordan en tabels attributter er forbundet.
- Ved brug af ER modelling forholdet mellem komponenterne i dataene opretholdes.
- I logisk skema er forskellige integritetsbegrænsninger defineret for at opretholde kvaliteten af indsættelse og opdatere dataene.
Se databaseskema
- Det er et visningsniveaudesign, som er i stand til at definere interaktionen mellem slutbruger og database.
- Brugeren er i stand til at interagere med databasen ved hjælp af grænsefladen uden at vide meget om den lagrede mekanisme for data i databasen.
Tre-lags skemadesign
java operatører
Oprettelse af databaseskema
Til oprettelse af et skema bruges sætningen CREATE SCHEMA i hver database. Men forskellige databaser har forskellig betydning for dette. Nedenfor vil vi se på nogle udsagn til oprettelse af et databaseskema i forskellige databasesystemer:
1. MySQL: I MySQL bruger vi CREATE SCHEMA-sætningen til at oprette databasen, fordi i MySQL CREATE SCHEMA og CREATE DATABASE er begge sætninger ens.
2. SQL Server: I SQL Server bruger vi CREATE SCHEMA-sætningen til at oprette et nyt skema.
3. Oracle-database: I Oracle Database bruger vi CREATE USER til at oprette et nyt skema, fordi der i Oracle-databasen allerede er oprettet et skema med hver databasebruger. Sætningen CREATE SCHEMA opretter ikke et skema, i stedet udfylder det skemaet med tabeller og visninger og giver dig også adgang til disse objekter uden at skulle bruge flere SQL-sætninger for flere transaktioner.
Design af databaseskemaer
Der er mange måder at strukturere en database på, og vi bør bruge det bedst egnede skemadesign til at skabe vores database, fordi ineffektive skemadesigns er svære at administrere og forbruge ekstra hukommelse og ressourcer.
java hello world eksempel
Skemadesign afhænger for det meste af applikationens krav. Her har vi nogle effektive skemadesigns til at skabe vores applikationer, lad os tage et kig på skemadesignerne:
- Flad model
- Hierarkisk model
- Netværksmodel
- Relationel model
- Stjerneskema
- Snefnug-skema
Flad model
Et fladt modelskema er et 2-D-array, hvor hver kolonne indeholder den samme type data/information, og elementerne med rækker er relateret til hinanden. Det er ligesom en tabel eller et regneark. Dette skema er bedre til små applikationer, der ikke indeholder komplekse data.
Design af flad model
Hierarkisk model
Data er arrangeret ved hjælp af forældre-barn-relationer og en trælignende struktur i den hierarkiske databasemodel. Fordi hver post består af flere børn og en forælder, kan den bruges til at illustrere en-til-mange-relationer i diagrammer, såsom organisationsdiagrammer. Selvom det er indlysende, er det måske ikke så tilpasningsdygtigt i komplicerede partnerskaber.
Design af hierarkisk model
Netværksmodel
Netværksmodellen og den hierarkiske model er ret ens med en vigtig forskel, der er relateret til datarelationer. Netværksmodellen tillader mange-til-mange-relationer, mens hierarkiske modeller tillader en-til-mange-relationer.
java swing
Design af netværksmodel
Relationel model
Relationsmodellen bruges hovedsageligt til relationelle databaser, hvor data gemmes som tabellens relationer. Det her relationel model skema er bedre til objektorienteret programmering.
Design af relationel model
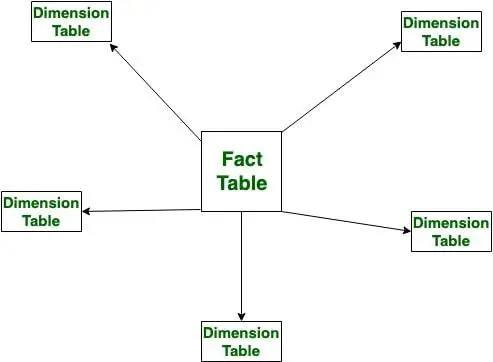
Stjerneskema
Stjerneskema er bedre til lagring og analyse af store mængder data. Den har en faktatabel i midten og flere dimensionstabeller forbundet til den ligesom en stjerne, hvor faktatabellen indeholder de numeriske data, der kører forretningsprocesser, og dimensionstabellen indeholder data relateret til dimensioner såsom produkt, tid, mennesker osv. eller vi kan sige, denne tabel indeholder beskrivelsen af faktatabellen. Stjerneskemaet giver os mulighed for at strukturere dataene for RDBMS .
Design af stjerneskema
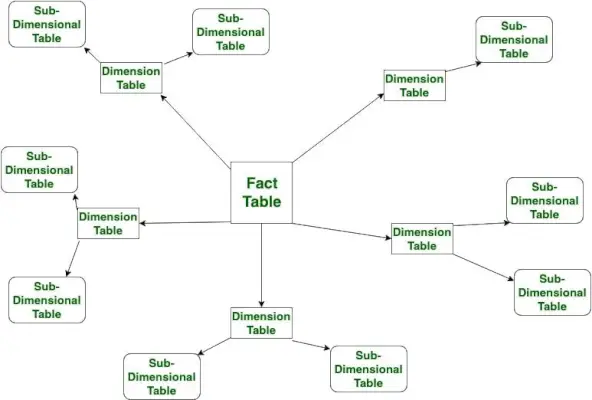
Snefnug-skema
Ligesom stjerneskemaet har snefnugskemaet også en faktatabel i midten og flere dimensionstabeller forbundet til sig, men den største forskel i begge modeller er, at i snefnugskema - dimensionstabeller er yderligere normaliseret til flere relaterede tabeller. Snefnugskemaet bruges til at analysere store mængder data.
Design af Snowflake Schema
Forskel mellem logisk og fysisk databaseskema
| Fysisk skema centerbillede i css | Logisk skema |
|---|---|
| Fysisk skema beskriver måden, hvorpå data lagres på disken. | Logisk skema giver den konceptuelle visning, der definerer forholdet mellem dataenhederne. |
| Har lavt abstraktionsniveau. | At have et højt abstraktionsniveau. |
| Designet af databasen er uafhængigt af ethvert databasestyringssystem. | Designet af en database skal fungere med et specifikt databasestyringssystem eller hardwareplatform. |
| Ændringer i fysisk skema påvirker det logiske skema | Eventuelle ændringer i logisk skema har minimal effekt i det fysiske skema |
| Fysisk skema inkluderer ikke attributter. | Logisk skema indeholder attributter. |
| Fysisk skema indeholder attributterne og deres datatyper. | Logisk skema indeholder ingen attributter eller datatyper. |
| Eksempler: Data definition sprog (DDL), lagerstrukturer, indekser. | Eksempler: Entitetsforholdsdiagram , Unified Modeling Language, klassediagram. |
Fordele ved Database Schema
- Tilvejebringelse af konsistens af data: Database skema sikrer datakonsistensen og forhindrer dubletter.
- Opretholdelse af skalerbarhed: Veldesignet databaseskema hjælper med at opretholde tilføjelse af nye tabeller i databasen sammen med, at det hjælper med at håndtere store mængder data i voksende tabeller.
- Ydeevneforbedring: Databaseskema hjælper med hurtigere datahentning, hvilket er i stand til at reducere driftstiden på databasetabellerne.
- Nem vedligeholdelse: Databaseskema hjælper med at vedligeholde hele databasen uden at påvirke resten af databasen
- Datasikkerhed: Databaseskema hjælper med at gemme de følsomme data og tillader kun autoriseret adgang til databasen.
Databaseforekomst
Databaseskemaet defineres før den faktiske database oprettes, efter at databasen er operationel, er det meget vanskeligt at ændre skemaet, fordi skemaet repræsenterer databasens grundlæggende struktur. Databaseforekomsten indeholder ingen information relateret til de gemte data i databasen. Derfor repræsenterer databaseinstansen de data og informationer, der i øjeblikket er lagret i databasen på et bestemt tidspunkt.

Databaseforekomst af kundetabel på et bestemt tidspunkt
Konklusion
- Databasens struktur omtales som skemaet, og det repræsenterer logiske begrænsninger som blandt andet tabel og nøgle.
- Tre skema arkitektur blev udviklet for at forhindre brugeren i at få direkte adgang til databasen.
- Da de oplysninger, der er gemt i databasen, er genstand for hyppige ændringer, er Instance en repræsentation af en data på et bestemt tidspunkt.