I den virkelige verden har ikke alle data, vi arbejder på, en målvariabel. Denne form for data kan ikke analyseres ved hjælp af overvågede læringsalgoritmer. Vi har brug for hjælp fra uovervågede algoritmer. En af de mest populære typer analyser under uovervåget læring er kundesegmentering til målrettede annoncer eller i medicinsk billedbehandling for at finde ukendte eller nye inficerede områder og mange flere tilfælde, som vi vil diskutere yderligere i denne artikel.
Indholdsfortegnelse
- Hvad er Clustering?
- Typer af klyngedannelse
- Anvendelser af Clustering
- Typer af klyngealgoritmer
- Anvendelser af Clustering på forskellige områder:
- Ofte stillede spørgsmål (FAQ) om klyngedannelse
Hvad er Clustering?
Opgaven med at gruppere datapunkter baseret på deres lighed med hinanden kaldes Clustering eller Cluster Analysis. Denne metode er defineret under grenen af Uovervåget læring , som har til formål at få indsigt fra umærkede datapunkter, det vil sige i modsætning til overvåget læring vi har ikke en målvariabel.
Clustering sigter mod at danne grupper af homogene datapunkter fra et heterogent datasæt. Den evaluerer ligheden baseret på en metrik som euklidisk afstand, Cosinus-lighed, Manhattan-afstand osv. og grupperer derefter de punkter med den højeste lighedsscore sammen.
For eksempel, i grafen nedenfor, kan vi tydeligt se, at der dannes 3 cirkulære klynger på basis af afstand.
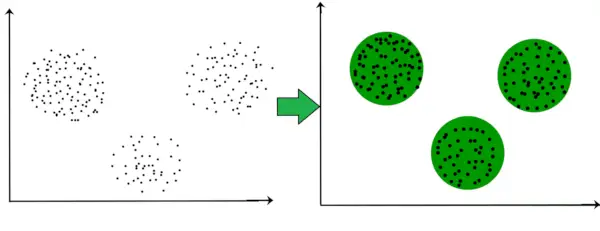
Nu er det ikke nødvendigt, at de dannede klynger skal være cirkulære i form. Formen på klynger kan være vilkårlig. Der er mange algoritmer, der fungerer godt med at detektere vilkårligt formede klynger.
For eksempel, i nedenstående givne graf kan vi se, at de dannede klynger ikke er cirkulære i form.
prologsprog

Typer af klyngedannelse
I store træk er der 2 typer clustering, der kan udføres for at gruppere lignende datapunkter:
- Hård gruppering: I denne type klynge tilhører hvert datapunkt en klynge fuldstændigt eller ej. Lad os for eksempel sige, at der er 4 datapunkter, og vi skal gruppere dem i 2 klynger. Så hvert datapunkt vil enten tilhøre klynge 1 eller klynge 2.
| Datapunkter | Klynger |
|---|---|
| EN | C1 |
| B | C2 |
| C | C2 |
| D | C1 |
- Blød klynger: I denne type klynge, i stedet for at tildele hvert datapunkt til en separat klynge, evalueres en sandsynlighed eller sandsynlighed for, at det punkt er den klynge. Lad os for eksempel sige, at der er 4 datapunkter, og vi skal gruppere dem i 2 klynger. Så vi vil evaluere sandsynligheden for, at et datapunkt tilhører begge klynger. Denne sandsynlighed beregnes for alle datapunkter.
| Datapunkter | Sandsynlighed for C1 | Sandsynlighed for C2 |
| EN | 0,91 | 0,09 |
| B | 0,3 | 0,7 |
| C | 0,17 | 0,83 |
| D | 1 | 0 |
Anvendelser af Clustering
Nu, før vi begynder med typer af klyngealgoritmer, vil vi gennemgå brugen af klyngealgoritmer. Klyngealgoritmer bruges hovedsageligt til:
- Markedssegmentering – Virksomheder bruger clustering til at gruppere deres kunder og bruger målrettede annoncer til at tiltrække flere publikum.
- Social netværksanalyse – Sociale medier bruger dine data til at forstå din browseradfærd og give dig målrettede venneanbefalinger eller indholdsanbefalinger.
- Medicinsk billeddannelse - Læger bruger Clustering til at finde ud af syge områder i diagnostiske billeder som røntgenstråler.
- Anomali detektion – For at finde outliers i en strøm af realtidsdatasæt eller prognoser for svigagtige transaktioner kan vi bruge klyngedannelse til at identificere dem.
- Forenkle arbejdet med store datasæt – Hver klynge får et klynge-id efter klyngedannelsen er fuldført. Nu kan du reducere et funktionssæts hele funktionssæt til dets klynge-id. Klyngedannelse er effektiv, når den kan repræsentere en kompliceret sag med et ligetil klynge-id. Ved at bruge samme princip kan klyngedata gøre komplekse datasæt enklere.
Der er mange flere use cases til clustering, men der er nogle af de store og almindelige use cases af clustering. Fremover vil vi diskutere klyngealgoritmer, der vil hjælpe dig med at udføre ovenstående opgaver.
Typer af klyngealgoritmer
På overfladeniveau hjælper klyngedannelse i analysen af ustrukturerede data. Graftegning, den korteste afstand og tætheden af datapunkterne er nogle af de elementer, der påvirker klyngedannelsen. Clustering er processen med at bestemme, hvor relaterede objekterne er baseret på en metrik kaldet lighedsmålet. Lighedsmålinger er nemmere at finde i mindre sæt funktioner. Det bliver sværere at skabe lighedsmål, efterhånden som antallet af funktioner stiger. Afhængigt af typen af klyngealgoritme, der anvendes i data mining, anvendes flere teknikker til at gruppere dataene fra datasættene. I denne del beskrives klyngeteknikkerne. Forskellige typer klyngealgoritmer er:
- Centroid-baseret Clustering (partitioneringsmetoder)
- Tæthedsbaseret clustering (modelbaserede metoder)
- Forbindelsesbaseret clustering (hierarkisk clustering)
- Distributionsbaseret Clustering
Vi vil kort gennemgå hver af disse typer.
1. Partitioneringsmetoder er de letteste klyngealgoritmer. De grupperer datapunkter ud fra deres nærhed. Generelt er lighedsmålene valgt for disse algoritmer Euklidian distance, Manhattan Distance eller Minkowski Distance. Datasættene er adskilt i et forudbestemt antal klynger, og hver klynge refereres af en vektor af værdier. Sammenlignet med vektorværdien viser inputdatavariablen ingen forskel og slutter sig til klyngen.
Den primære ulempe ved disse algoritmer er kravet om, at vi etablerer antallet af klynger, k, enten intuitivt eller videnskabeligt (ved hjælp af albuemetoden), før et clustering-maskinlæringssystem begynder at allokere datapunkterne. På trods af dette er det stadig den mest populære form for clustering. K-betyder og K-medoider clustering er nogle eksempler på denne type clustering.
2. Tæthedsbaseret clustering (modelbaserede metoder)
Tæthedsbaseret clustering, en modelbaseret metode, finder grupper baseret på tætheden af datapunkter. I modsætning til tyngdepunktsbaseret clustering, som kræver, at antallet af klynger er foruddefineret og er følsom over for initialisering, bestemmer tæthedsbaseret clustering antallet af klynger automatisk og er mindre modtagelig for startpositioner. De er gode til at håndtere klynger af forskellige størrelser og former, hvilket gør dem velegnede til datasæt med uregelmæssigt formede eller overlappende klynger. Disse metoder håndterer både tætte og sparsomme dataregioner ved at fokusere på lokal tæthed og kan skelne klynger med en række forskellige morfologier.
I modsætning hertil har tyngdepunktsbaseret gruppering, ligesom k-middel, problemer med at finde vilkårligt formede klynger. På grund af dets forudindstillede antal klyngekrav og ekstreme følsomhed over for den indledende positionering af tyngdepunkter, kan resultaterne variere. Desuden begrænser tendensen med tyngdepunktsbaserede tilgange til at producere sfæriske eller konvekse klynger deres evne til at håndtere komplicerede eller uregelmæssigt formede klynger. Som konklusion overvinder tæthedsbaseret klyngning ulemperne ved tyngdepunktsbaserede teknikker ved autonomt at vælge klyngestørrelser, være modstandsdygtig over for initialisering og med succes fange klynger af forskellige størrelser og former. Den mest populære tæthedsbaserede klyngealgoritme er DBSCAN .
3. Forbindelsesbaseret clustering (hierarkisk clustering)
En metode til at samle relaterede datapunkter i hierarkiske klynger kaldes hierarkisk clustering. Hvert datapunkt tages i første omgang i betragtning som en separat klynge, som efterfølgende kombineres med de klynge, der ligner mest, for at danne en stor klynge, der indeholder alle datapunkterne.
Tænk over, hvordan du kan arrangere en samling af genstande baseret på, hvor ens de er. Hvert objekt begynder som sin egen klynge i bunden af træet, når der bruges hierarkisk klyngedannelse, som skaber et dendrogram, en trælignende struktur. De nærmeste parringer af klynger kombineres derefter til større klynger, efter at algoritmen har undersøgt, hvor ens objekterne er hinanden. Når hvert objekt er i en klynge øverst i træet, er fletningsprocessen afsluttet. At udforske forskellige granularitetsniveauer er en af de sjove ting ved hierarkisk klyngedannelse. For at opnå et givet antal klynger kan du vælge at skære dendrogram i en bestemt højde. Jo mere ens to objekter er i en klynge, jo tættere er de. Det kan sammenlignes med at klassificere genstande efter deres stamtræer, hvor de nærmeste slægtninge er klynget sammen, og de bredere grene betyder mere generelle forbindelser. Der er 2 tilgange til hierarkisk klyngedannelse:
- Splittende klyngedannelse : Det følger en top-down tilgang, her betragter vi alle datapunkter som en del af en stor klynge, og derefter opdeles denne klynge i mindre grupper.
- Agglomerativ klyngedannelse : Det følger en bottom-up tilgang, her betragter vi alle datapunkter som en del af individuelle klynger, og så bliver disse klynger slået sammen for at lave én stor klynge med alle datapunkter.
4. Distributionsbaseret Clustering
Ved hjælp af distributionsbaseret clustering genereres og organiseres datapunkter i henhold til deres tilbøjelighed til at falde ind i den samme sandsynlighedsfordeling (såsom en Gaussisk, binomial eller andet) i dataene. Dataelementerne er grupperet ved hjælp af en sandsynlighedsbaseret fordeling, der er baseret på statistiske fordelinger. Inkluderet er dataobjekter, der har større sandsynlighed for at være i klyngen. Det er mindre sandsynligt, at et datapunkt inkluderes i en klynge, jo længere det er fra klyngens centrale punkt, som findes i hver klynge.
En bemærkelsesværdig ulempe ved tætheds- og grænsebaserede tilgange er behovet for at specificere klyngerne a priori for nogle algoritmer, og primært definitionen af klyngeformen for hovedparten af algoritmer. Der skal være valgt mindst én tuning eller hyper-parameter, og selvom det burde være enkelt, kan det have uventede konsekvenser at få det forkerte. Distributionsbaseret klyngedannelse har en klar fordel i forhold til nærheds- og tyngdepunktsbaserede klyngetilgange med hensyn til fleksibilitet, nøjagtighed og klyngestruktur. Det centrale spørgsmål er, at for at undgå overfitting , fungerer mange klyngemetoder kun med simulerede eller fremstillede data, eller når hovedparten af datapunkterne bestemt tilhører en forudindstillet distribution. Den mest populære distributionsbaserede klyngealgoritme er Gaussisk blandingsmodel .
Anvendelser af Clustering på forskellige områder:
- Marketing: Det kan bruges til at karakterisere og opdage kundesegmenter til markedsføringsformål.
- Biologi: Det kan bruges til klassificering blandt forskellige arter af planter og dyr.
- Biblioteker: Det bruges til at gruppere forskellige bøger på baggrund af emner og information.
- Forsikring: Det bruges til at anerkende kunderne, deres politikker og identificere svindel.
- Byplanlægning: Det bruges til at lave grupper af huse og til at studere deres værdier baseret på deres geografiske placering og andre tilstedeværende faktorer.
- Jordskælvsundersøgelser: Ved at lære de jordskælvsramte områder kan vi bestemme de farlige zoner.
- Billedbehandling : Clustering kan bruges til at gruppere lignende billeder sammen, klassificere billeder baseret på indhold og identificere mønstre i billeddata.
- Genetik: Clustering bruges til at gruppere gener, der har lignende ekspressionsmønstre, og identificere gennetværk, der arbejder sammen i biologiske processer.
- Finansiere: Clustering bruges til at identificere markedssegmenter baseret på kundeadfærd, identificere mønstre i aktiemarkedsdata og analysere risiko i investeringsporteføljer.
- Kunde service: Clustering bruges til at gruppere kundehenvendelser og -klager i kategorier, identificere fælles problemer og udvikle målrettede løsninger.
- Fremstilling : Clustering bruges til at gruppere lignende produkter sammen, optimere produktionsprocesser og identificere defekter i fremstillingsprocesser.
- Medicinsk diagnose: Clustering bruges til at gruppere patienter med lignende symptomer eller sygdomme, hvilket hjælper med at stille præcise diagnoser og identificere effektive behandlinger.
- Opdagelse af svindel: Clustering bruges til at identificere mistænkelige mønstre eller anomalier i finansielle transaktioner, hvilket kan hjælpe med at opdage svindel eller anden økonomisk kriminalitet.
- Trafikanalyse: Clustering bruges til at gruppere lignende mønstre af trafikdata, såsom spidsbelastningstider, ruter og hastigheder, hvilket kan hjælpe med at forbedre transportplanlægning og infrastruktur.
- Analyse af sociale netværk: Clustering bruges til at identificere fællesskaber eller grupper inden for sociale netværk, som kan hjælpe med at forstå social adfærd, indflydelse og tendenser.
- Cybersikkerhed: Clustering bruges til at gruppere lignende mønstre for netværkstrafik eller systemadfærd, som kan hjælpe med at opdage og forhindre cyberangreb.
- Klimaanalyse: Clustering bruges til at gruppere lignende mønstre af klimadata, såsom temperatur, nedbør og vind, som kan hjælpe med at forstå klimaændringer og deres indvirkning på miljøet.
- Sportsanalyse: Clustering bruges til at gruppere lignende mønstre af spiller- eller teampræstationsdata, som kan hjælpe med at analysere spillerens eller teamets styrker og svagheder og træffe strategiske beslutninger.
- Kriminalitetsanalyse: Clustering bruges til at gruppere lignende mønstre af kriminalitetsdata, såsom sted, tidspunkt og type, hvilket kan hjælpe med at identificere kriminalitetshotspots, forudsige fremtidige kriminalitetstendenser og forbedre kriminalitetsforebyggende strategier.
Konklusion
I denne artikel diskuterede vi Clustering, dets typer, og dets applikationer i den virkelige verden. Der er meget mere, der skal dækkes i uovervåget læring, og klyngeanalyse er kun det første skridt. Denne artikel kan hjælpe dig i gang med Clustering-algoritmer og hjælpe dig med at få et nyt projekt, der kan føjes til din portefølje.
Ofte stillede spørgsmål (FAQ) om klyngedannelse
Q. Hvad er den bedste klyngemetode?
De 10 bedste klyngealgoritmer er:
- K-betyder Clustering
- Hierarkisk klyngedannelse
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
- Gaussiske blandingsmodeller (GMM)
- Agglomerativ klyngedannelse
- Spektral Clustering
- Mean Shift Clustering
- Affinitetsudbredelse
- OPTICS (bestillingspunkter for at identificere klyngestrukturen)
- Birch (Balanceret iterativ reduktion og klyngedannelse ved hjælp af hierarkier)
Q. Hvad er forskellen mellem klyngedannelse og klassificering?
Den største forskel mellem clustering og klassificering er, at klassificering er en overvåget læringsalgoritme, og clustering er en uovervåget læringsalgoritme. Det vil sige, at vi anvender clustering på de datasæt, der ikke har en målvariabel.
Sp. Hvad er fordelene ved klyngeanalyse?
Data kan organiseres i meningsfulde grupper ved hjælp af det stærke analytiske værktøj klyngeanalyse. Du kan bruge det til at lokalisere segmenter, finde skjulte mønstre og forbedre beslutninger.
Q. Hvilken er den hurtigste klyngemetode?
K-betyder klyngedannelse betragtes ofte som den hurtigste klyngemetode på grund af dens enkelhed og beregningseffektivitet. Det tildeler iterativt datapunkter til det nærmeste klyngetyngdepunkt, hvilket gør det velegnet til store datasæt med lav dimensionalitet og et moderat antal klynger.
Sp. Hvad er begrænsningerne ved klyngedannelse?
Begrænsninger ved klyngedannelse omfatter følsomhed over for startbetingelser, afhængighed af valg af parametre, vanskeligheder med at bestemme det optimale antal klynger og udfordringer med at håndtere højdimensionelle eller støjende data.
Q. Hvad afhænger kvaliteten af resultatet af klyngedannelse af?
Kvaliteten af klyngeresultater afhænger af faktorer såsom valg af algoritme, afstandsmetrik, antal klynger, initialiseringsmetode, dataforbehandlingsteknikker, klyngeevalueringsmetrikker og domæneviden. Disse elementer påvirker tilsammen effektiviteten og nøjagtigheden af klyngeresultatet.