Linux uniq-kommando bruges til at fjerne alle de gentagne linjer fra en fil. Det kan også bruges til at vise et antal af ethvert ord, kun gentagne linjer, ignorere tegn og sammenligne specifikke felter. Det er en af de mest brugte kommandoer i Linux system. Det bruges ofte sammen med sorteringskommando fordi den sammenligner tilstødende tegn. Den kasserer alle de identiske linjer og skriver outputtet.
Syntaks:
uniq [OPTION]... [INPUT [OUTPUT]]
Muligheder:
Nogle nyttige kommandolinjeindstillinger for uniq-kommandoen er som følger:
-c, --tæller: det præfikser linjerne med antallet af forekomster.
-d, --gentaget: det bruges til at udskrive duplikerede linjer, en for hver gruppe.
-D: Det bruges til at udskrive alle duplikerede linjer.
--all-repeated[=METHOD]: Det ligner ret meget '-D'-indstillingen, forskellen mellem begge muligheder er, at den tillader adskillelse af grupper med en tom linje.
-f, --spring-felter=N: Det bruges til at undgå sammenligning af de første N felter.
--gruppe[=METODE]: Den bruges til at vise alle elementer og adskiller grupperne med en tom linje.
-i, --ignorer-case: Det bruges til at ignorere forskellene, mens man sammenligner.
-s, --skip-chars=N: Det bruges til at undgå sammenligning af de første N tegn.
-u, --unik: det bruges til at udskrive unikke linjer.
-z, --nul-termineret: Den bruges til linjeafgrænseren er NUL og ikke nylinjetilstand.
-w, --check-chars=N: Det bruges til at sammenligne ikke mere end N tegn i linjer.
--Hjælp: Det bruges til at vise hjælpedokumentation.
--version: Det bruges til at vise versionsoplysningerne.
Eksempler på uniq Command
Lad os se følgende eksempler på uniq-kommandoen:
- Fjern gentagne linjer
- tælle antallet af forekomster af et ord
- Vis de gentagne linjer
- Vis de unikke linjer
- Ignorer tegn i sammenligning
- Ignorer felter i sammenligning
Fjern gentagne linjer
For at fjerne gentagne linjer fra en fil skal du udføre den grundlæggende uniq-kommando som følger:
solrig deol alder
sort dupli.txt | uniq
Ovenstående kommando vil fjerne de duplikerede linjer fra filen 'dupli.txt'. Overvej nedenstående output:
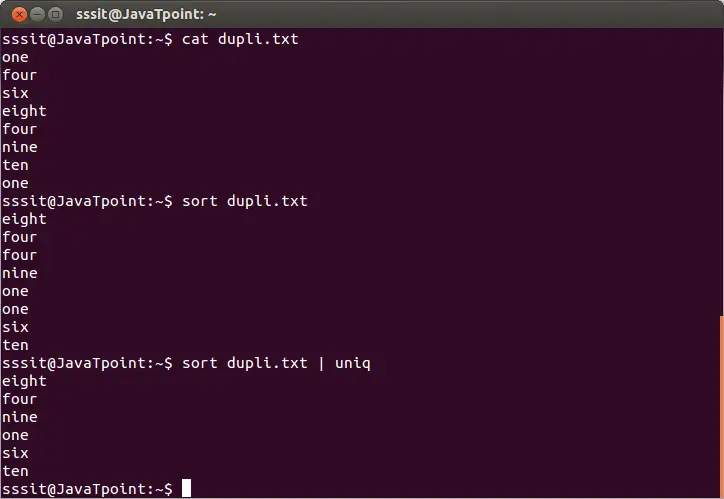
Fra ovenstående output ignoreres de gentagne ord.
Tæl antallet af forekomster af et ord
Vi kan tælle antallet af forekomster af et ord ved at bruge kommandoen uniq. Muligheden '-c' bruges til at tælle ordet. Udfør det som følger:
sort dupli.txt | uniq -c
Ovenstående kommando vil tælle de ord, der kommer i 'dupli.txt'. Overvej nedenstående output:

Fra ovenstående output, kommandoen 'sort dupli.txt | uniq -c' tæller antallet af gange et ord gentages.
Vis de gentagne linjer
'-d' muligheden bruges til kun at vise de gentagne linjer. Det vil kun vise de linjer, der vil være mere end én gang i en fil og skrive output til standard output. Overvej nedenstående kommando:
sort dupli.txt | uniq -d
Ovenstående kommando viser kun de gentagne linjer. Overvej nedenstående output:

Vis de unikke linjer
Muligheden '-u' bruges til kun at vise de unikke linjer (som ikke gentages). Den viser kun de linjer, der kun forekommer én gang, og skriver resultatet til standardoutput. Overvej nedenstående kommando:
sort dupli.txt | uniq -u
Ovenstående kommando vil kun vise de unikke linjer fra filen 'dupli.txt'. Overvej nedenstående output:

Ignorer tegn i sammenligning
Muligheden '-s' bruges til at ignorere tegnene i sammenligning. Det vil ignorere det angivne antal tegn og vise resultatet til standard output. Overvej nedenstående kommando:
sort dupli.txt | uniq -s 2
Ovenstående kommando vil ignorere de to første tegn i sammenligning fra filen 'dupli.txt'. Overvej nedenstående output:

Ignorer felter i sammenligning
Valgmuligheden '-f' bruges til at ignorere felterne. Overvej nedenstående kommando:
uniq -f 2 dupli2.txt
Ovenstående kommando vil ikke sammenligne de to første felter fra filen 'dupli2.txt'. Overvej nedenstående output:

Fra ovenstående output springes de to første felter over, og resten af alle felter sammenlignes fra filen 'dupli2.txt'.