Et vigtigt aspekt af Maskinelæring er modelevaluering. Du skal have en eller anden mekanisme til at evaluere din model. Det er her disse præstationsmålinger kommer ind i billedet, de giver os en fornemmelse af, hvor god en model er. Hvis du er bekendt med nogle af det grundlæggende vedr Maskinelæring så må du være stødt på nogle af disse målinger, såsom nøjagtighed, præcision, genkaldelse, auc-roc osv., som generelt bruges til klassifikationsopgaver. I denne artikel vil vi udforske en sådan metrik i dybden, som er AUC-ROC-kurven.
Indholdsfortegnelse
- Hvad er AUC-ROC kurven?
- Nøgletermer brugt i AUC og ROC Curve
- Forholdet mellem Sensitivitet, Specificitet, FPR og Threshold.
- Hvordan virker AUC-ROC?
- Hvornår skal vi bruge AUC-ROC-evalueringsmetrikken?
- Gætter på modellens ydeevne
- Forståelse af AUC-ROC-kurven
- Implementering ved hjælp af to forskellige modeller
- Hvordan bruger man ROC-AUC til en multi-klasse model?
- Ofte stillede spørgsmål til AUC ROC Curve i Machine Learning
Hvad er AUC-ROC kurven?
AUC-ROC-kurven, eller Area Under the Receiver Operation Characteristic-kurven, er en grafisk repræsentation af ydeevnen af en binær klassifikationsmodel ved forskellige klassifikationstærskler. Det bruges almindeligvis i maskinlæring til at vurdere en models evne til at skelne mellem to klasser, typisk den positive klasse (f.eks. tilstedeværelse af en sygdom) og den negative klasse (f.eks. fravær af en sygdom).
Lad os først forstå betydningen af de to udtryk ROC og AUC .
- ROC : Modtagerens driftsegenskaber
- AUC : Område under kurve
Receiver Operating Characteristics (ROC) kurve
ROC står for Receiver Operating Characteristics, og ROC-kurven er den grafiske repræsentation af effektiviteten af den binære klassifikationsmodel. Den plotter den sande positive rate (TPR) vs den falske positive rate (FPR) ved forskellige klassificeringstærskler.
Område under kurve (AUC) Kurve:
AUC står for Area Under the Curve, og AUC-kurven repræsenterer arealet under ROC-kurven. Den måler den overordnede ydeevne af den binære klassifikationsmodel. Da både TPR og FPR ligger mellem 0 og 1, så vil området altid ligge mellem 0 og 1, og En større værdi af AUC angiver bedre modelydelse. Vores hovedmål er at maksimere dette område for at have den højeste TPR og laveste FPR ved den givne tærskel. AUC måler sandsynligheden for, at modellen vil tildele en tilfældigt valgt positiv forekomst en højere forudsagt sandsynlighed sammenlignet med en tilfældigt valgt negativ forekomst.
Det repræsenterer sandsynlighed hvormed vores model kan skelne mellem de to klasser, der er til stede i vores mål.
ROC-AUC Klassifikation Evaluering Metric
Nøgletermer brugt i AUC og ROC Curve
1. TPR og FPR
Dette er den mest almindelige definition, du ville være stødt på, når du ville Google AUC-ROC. Grundlæggende er ROC-kurven en graf, der viser ydeevnen af en klassifikationsmodel ved alle mulige tærskler (tærskel er en bestemt værdi, udover hvilken du siger, at et punkt tilhører en bestemt klasse). Kurven er plottet mellem to parametre
- TPR – Ægte positiv sats
- FPR – Falsk positiv rate
Før vi forstår, lader TPR og FPR os hurtigt se på forvirringsmatrix .
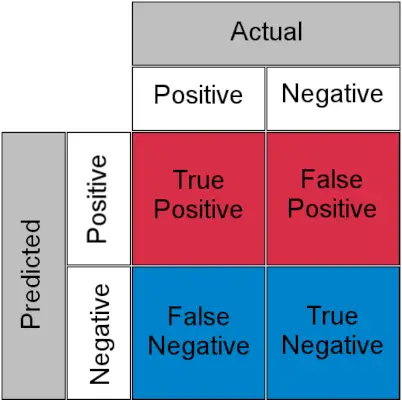
Forvirringsmatrix for en klassifikationsopgave
- Ægte positiv : Faktisk positiv og forudsagt som positiv
- Ægte negativ : Faktisk negativ og forudsagt som negativ
- Falsk positiv (Type I-fejl) : Faktisk negativ, men forudsagt som positiv
- Falsk negativ (Type II-fejl) : Faktisk positiv, men forudsagt som negativ
Enkelt sagt kan du kalde falsk positiv en falsk alarm og falsk negativ a gå glip af . Lad os nu se på, hvad TPR og FPR er.
2. Følsomhed / Sand positiv rate / Genkaldelse
Grundlæggende er TPR/Recall/Sensitivity forholdet mellem positive eksempler, der er korrekt identificeret. Det repræsenterer modellens evne til korrekt at identificere positive tilfælde og beregnes som følger:

Sensitivitet/Recall/TPR måler andelen af faktiske positive tilfælde, som er korrekt identificeret af modellen som positive.
3. Falsk positiv rate
FPR er forholdet mellem negative eksempler, der er forkert klassificeret.

4. Specificitet
Specificitet måler andelen af faktiske negative tilfælde, som er korrekt identificeret af modellen som negative. Det repræsenterer modellens evne til korrekt at identificere negative tilfælde

Og som tidligere nævnt er ROC intet andet end plottet mellem TPR og FPR på tværs af alle mulige tærskler, og AUC er hele området under denne ROC-kurve.
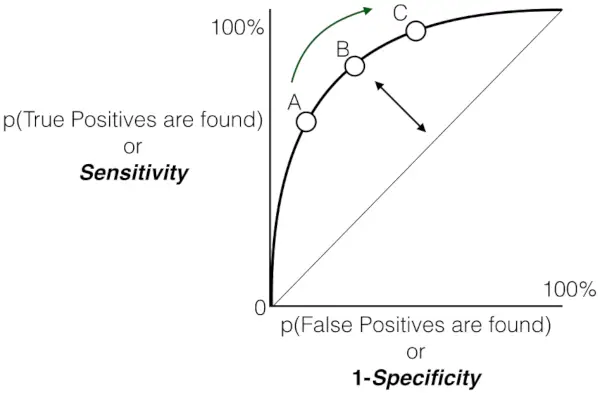
Følsomhed versus Falsk Positiv Rate plot
Forholdet mellem Sensitivitet, Specificitet, FPR og Threshold .
Følsomhed og specificitet:
- Omvendt forhold: sensitivitet og specificitet har en omvendt sammenhæng. Når den ene stiger, har den anden en tendens til at falde. Dette afspejler den iboende afvejning mellem sande positive og sande negative kurser.
- Tuning via Threshold: Ved at justere tærskelværdien kan vi kontrollere balancen mellem sensitivitet og specificitet. Lavere tærskler fører til højere sensitivitet (flere sande positive) på bekostning af specificitet (flere falske positive). Omvendt øger en hævning af tærsklen specificiteten (færre falske positiver), men ofrer følsomheden (flere falske negativer).
Tærskel og falsk positiv rate (FPR):
- FPR og specificitetsforbindelse: Falsk Positiv Rate (FPR) er simpelthen komplementet til specificitet (FPR = 1 – specificitet). Dette betyder det direkte forhold mellem dem: højere specificitet oversættes til lavere FPR og omvendt.
- FPR-ændringer med TPR: På samme måde, som du har bemærket, er True Positive Rate (TPR) og FPR også forbundet. En stigning i TPR (mere sande positive) fører generelt til en stigning i FPR (flere falske positive). Omvendt resulterer et fald i TPR (færre sande positive) i et fald i FPR (færre falske positive)
Hvordan virker AUC-ROC?
Vi så på den geometriske fortolkning, men jeg gætter på, at det stadig ikke er nok til at udvikle intuitionen bag, hvad 0,75 AUC faktisk betyder, lad os nu se på AUC-ROC fra et sandsynlighedssynspunkt. Lad os først tale om, hvad AUC gør, og senere vil vi bygge vores forståelse oven på dette
AUC måler, hvor godt en model er i stand til at skelne mellem klasser.
En AUC på 0,75 ville faktisk betyde, at lad os sige, at vi tager to datapunkter, der tilhører separate klasser, så er der en 75 % chance for, at modellen ville være i stand til at adskille dem eller rangordne dem korrekt, dvs. positivt punkt har en højere forudsigelsessandsynlighed end det negative klasse. (hvis det antages, at en højere forudsigelsessandsynlighed betyder, at punktet ideelt set ville tilhøre den positive klasse). Her er et lille eksempel for at gøre tingene mere klare.
Indeks | Klasse | Sandsynlighed |
|---|---|---|
P1 | 1 | 0,95 |
P2 | 1 | 0,90 |
P3 | 0 | 0,85 |
P4 | 0 | 0,81 |
P5 | 1 | 0,78 |
P6 | 0 | 0,70 |
Her har vi 6 punkter, hvor P1, P2 og P5 hører til klasse 1 og P3, P4 og P6 hører til klasse 0, og vi er tilsvarende forudsagte sandsynligheder i Sandsynlighedskolonnen, som vi sagde, hvis vi tager to punkter, der tilhører adskilt klasser, hvad er så sandsynligheden for, at modellen rangordner dem korrekt.
Vi vil tage alle mulige par således at det ene point tilhører klasse 1 og det andet hører til klasse 0, vi vil have i alt 9 sådanne par nedenfor er alle disse 9 mulige par.
Par | er korrekt |
|---|---|
(P1,P3) | Ja |
(P1,P4) | Ja |
(P1,P6) | Ja |
(P2,P3) | Ja |
(P2,P4) | Ja |
(P2,P6) | Ja c# switch |
(P3,P5) | Ingen |
(P4,P5) | Ingen |
(P5,P6) | Ja |
Her fortæller kolonnen er Korrekt, om det nævnte par er korrekt rangordnet baseret på den forudsagte sandsynlighed, dvs. klasse 1 point har en højere sandsynlighed end klasse 0 point, i 7 ud af disse 9 mulige par er klasse 1 rangeret højere end klasse 0, eller vi kan sige, at der er en 77% chance for, at hvis du vælger et par point, der tilhører separate klasser, vil modellen være i stand til at skelne dem korrekt. Nu tror jeg, at du måske har en smule intuition bag dette AUC-nummer, bare for at fjerne yderligere tvivl, lad os validere det ved hjælp af Scikit learns AUC-ROC implementering.
Python3
import> numpy as np> from> sklearn .metrics>import> roc_auc_score> y_true>=> [>1>,>1>,>0>,>0>,>1>,>0>]> y_pred>=> [>0.95>,>0.90>,>0.85>,>0.81>,>0.78>,>0.70>]> auc>=> np.>round>(roc_auc_score(y_true, y_pred),>3>)> print>(>'Auc for our sample data is {}'>.>format>(auc))> |
>
>
Produktion:
AUC for our sample data is 0.778>
Hvornår skal vi bruge AUC-ROC-evalueringsmetrikken?
Der er nogle områder, hvor det måske ikke er ideelt at bruge ROC-AUC. I tilfælde, hvor datasættet er meget ubalanceret, ROC-kurven kan give en alt for optimistisk vurdering af modellens ydeevne . Denne optimisme-bias opstår, fordi ROC-kurvens falsk positive rate (FPR) kan blive meget lille, når antallet af faktiske negativer er stort.
Ser man på FPR-formlen,

vi observerer ,
- Den negative klasse er i flertal, nævneren af FPR er domineret af True Negatives, på grund af hvilke FPR bliver mindre følsom over for ændringer i forudsigelser relateret til minoritetsklassen (positiv klasse).
- ROC-kurver kan være passende, når omkostningerne ved falske positive og falske negative er afbalancerede, og datasættet ikke er stærkt ubalanceret.
I så fald Præcisions-genkaldelseskurver kan bruges, som giver en alternativ evalueringsmetrik, der er mere egnet til ubalancerede datasæt, med fokus på klassifikatorens ydeevne med hensyn til den positive (minoritets)klasse.
Gætter på modellens ydeevne
- En høj AUC (tæt på 1) indikerer fremragende diskriminerende kraft. Dette betyder, at modellen er effektiv til at skelne mellem de to klasser, og dens forudsigelser er pålidelige.
- En lav AUC (tæt på 0) tyder på dårlig ydeevne. I dette tilfælde kæmper modellen for at skelne mellem de positive og negative klasser, og dens forudsigelser er muligvis ikke troværdige.
- AUC omkring 0,5 indebærer, at modellen i det væsentlige foretager tilfældige gæt. Den viser ingen evne til at adskille klasserne, hvilket indikerer, at modellen ikke lærer nogen meningsfulde mønstre fra dataene.
Forståelse af AUC-ROC-kurven
I en ROC-kurve repræsenterer x-aksen typisk False Positive Rate (FPR), og y-aksen repræsenterer True Positive Rate (TPR), også kendt som Sensitivity eller Recall. Så en højere x-akseværdi (mod højre) på ROC-kurven indikerer en højere False Positive Rate, og en højere y-akseværdi (mod toppen) indikerer en højere True Positive Rate. ROC-kurven er en grafisk repræsentation af afvejningen mellem sand positiv rate og falsk positiv rate ved forskellige tærskler. Den viser ydeevnen af en klassifikationsmodel ved forskellige klassifikationstærskler. AUC (Area Under the Curve) er et sammenfattende mål for ROC-kurvens ydeevne. Valget af tærskelværdien afhænger af de specifikke krav til det problem, du forsøger at løse, og afvejningen mellem falske positive og falske negative, dvs. acceptabel i din sammenhæng.
- Hvis du vil prioritere at reducere falske positiver (minimere chancerne for at stemple noget som positivt, når det ikke er det), kan du vælge en tærskel, der resulterer i en lavere falsk positiv rate.
- Hvis du vil prioritere at øge sande positive (indfange så mange faktiske positive som muligt), kan du vælge en tærskel, der resulterer i en højere sand positiv rate.
Lad os overveje et eksempel for at illustrere, hvordan ROC-kurver genereres for forskellige tærskler og hvordan en bestemt tærskel svarer til en forvirringsmatrix. Antag, at vi har en binært klassifikationsproblem med en model, der forudsiger, om en e-mail er spam (positiv) eller ikke spam (negativ).
Lad os overveje de hypotetiske data,
Ægte etiketter: [1, 0, 1, 0, 1, 1, 0, 0, 1, 0]
Forudsagte sandsynligheder: [0,8, 0,3, 0,6, 0,2, 0,7, 0,9, 0,4, 0,1, 0,75, 0,55]
Tilfælde 1: Tærskelværdi = 0,5
Ægte etiketter | Forudsagte sandsynligheder | Forudsagte etiketter |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Forvirringsmatrix baseret på ovenstående forudsigelser
| Forudsigelse = 0 | Forudsigelse = 1 |
|---|---|---|
Faktisk = 0 | TP=4 | FN=1 |
Faktisk = 1 | FP=0 | TN=5 |
Derfor,
- True Positive Rate (TPR) :
Andel af faktiske positive korrekt identificeret af klassificeringsorganet er

- Falsk positiv rate (FPR) :
Andel af faktiske negativer, der er forkert klassificeret som positive



Så ved tærsklen på 0,5:
- Sand positiv rate (følsomhed): 0,8
- Falsk positiv rate: 0
Fortolkningen er, at modellen ved denne tærskel korrekt identificerer 80% af faktiske positive (TPR), men forkert klassificerer 0% af faktiske negative som positive (FPR).
Derfor vil vi for forskellige tærskler få,
Tilfælde 2: Tærskel = 0,7
Ægte etiketter | Forudsagte sandsynligheder | Forudsagte etiketter |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 delvis afhængighed | 0 |
| 1 | 0,6 | 0 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 0 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 0 |
Forvirringsmatrix baseret på ovenstående forudsigelser
| Forudsigelse = 0 | Forudsigelse = 1 |
|---|---|---|
Faktisk = 0 | TP=5 | FN=0 |
Faktisk = 1 | FP=2 | TN=3 |
Derfor,
- True Positive Rate (TPR) :
Andel af faktiske positive korrekt identificeret af klassificeringsorganet er

- Falsk positiv rate (FPR) :
Andel af faktiske negativer, der er forkert klassificeret som positive



Tilfælde 3: Tærskel = 0,4
Ægte etiketter | Forudsagte sandsynligheder | Forudsagte etiketter |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Forvirringsmatrix baseret på ovenstående forudsigelser
| Forudsigelse = 0 | Forudsigelse = 1 |
|---|---|---|
Faktisk = 0 | TP=4 | FN=1 |
Faktisk = 1 | FP=0 | TN=5 |
Derfor,
- True Positive Rate (TPR) :
Andel af faktiske positive korrekt identificeret af klassificeringsorganet er
- Falsk positiv rate (FPR) :
Andel af faktiske negativer, der er forkert klassificeret som positive
Tilfælde 4: Tærskel = 0,2
Ægte etiketter | Forudsagte sandsynligheder | Forudsagte etiketter |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 1 |
| 1 css ombryd tekst | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 1 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Forvirringsmatrix baseret på ovenstående forudsigelser
| Forudsigelse = 0 | Forudsigelse = 1 |
|---|---|---|
Faktisk = 0 | TP=2 | FN=3 |
Faktisk = 1 | FP=0 | TN=5 |
Derfor,
- True Positive Rate (TPR) :
Andel af faktiske positive korrekt identificeret af klassificeringsorganet er

- Falsk positiv rate (FPR) :
Andel af faktiske negativer, der er forkert klassificeret som positive

Tilfælde 5: Tærskelværdi = 0,85
Ægte etiketter | Forudsagte sandsynligheder | Forudsagte etiketter |
|---|---|---|
| 1 | 0,8 | 0 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 0 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 0 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 0 |
| 0 | 0,55 | 0 |
Forvirringsmatrix baseret på ovenstående forudsigelser
| Forudsigelse = 0 | Forudsigelse = 1 |
|---|---|---|
Faktisk = 0 | TP=5 | FN=0 |
Faktisk = 1 | FP=4 | TN=1 |
Derfor,
- True Positive Rate (TPR) :
Andel af faktiske positive korrekt identificeret af klassificeringsorganet er
- Falsk positiv rate (FPR) :
Andel af faktiske negativer, der er forkert klassificeret som positive


Baseret på ovenstående resultat vil vi plotte ROC-kurven
Python3
true_positive_rate>=> [>0.4>,>0.8>,>0.8>,>1.0>,>1>]> false_positive_rate>=> [>0>,>0>,>0>,>0.2>,>0.8>]> plt.plot(false_positive_rate, true_positive_rate,>'o-'>, label>=>'ROC'>)> plt.plot([>0>,>1>], [>0>,>1>],>'--'>, color>=>'grey'>, label>=>'Worst case'>)> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curve'>)> plt.legend()> plt.show()> |
>
>
Produktion:
Fra grafen antydes det, at:
- Den grå stiplede linje repræsenterer worst case-scenariet, hvor modellens forudsigelser, dvs. TPR er FPR, er de samme. Denne diagonale linje betragtes som det værst tænkelige scenarie, hvilket indikerer lige stor sandsynlighed for falske positive og falske negative.
- Da punkter afviger fra den tilfældige gættelinje mod det øverste venstre hjørne, forbedres modellens ydeevne.
- The Area Under the Curve (AUC) er et kvantitativt mål for modellens diskriminerende evne. En højere AUC-værdi, tættere på 1,0, indikerer overlegen ydeevne. Den bedst mulige AUC-værdi er 1,0, svarende til en model, der opnår 100 % sensitivitet og 100 % specificitet.
I det hele taget fungerer Receiver Operating Characteristic (ROC)-kurven som en grafisk repræsentation af afvejningen mellem en binær klassifikationsmodels True Positive Rate (sensitivitet) og False Positive Rate ved forskellige beslutningstærskler. Når kurven graciøst stiger mod det øverste venstre hjørne, betyder det modellens prisværdige evne til at skelne mellem positive og negative tilfælde på tværs af en række konfidensgrænser. Denne opadgående bane indikerer en forbedret ydeevne, med højere følsomhed opnået, samtidig med at falske positiver minimeres. De kommenterede tærskler, betegnet som A, B, C, D og E, giver værdifuld indsigt i modellens dynamiske adfærd på forskellige konfidensniveauer.
Implementering ved hjælp af to forskellige modeller
Installation af biblioteker
Python3
import> numpy as np> import> pandas as pd> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> |
>
>
For at træne Tilfældig Skov og Logistisk regression modeller og for at præsentere deres ROC-kurver med AUC-score, skaber algoritmen kunstige binære klassifikationsdata.
Generering af data og opdeling af data
Python3
# Generate synthetic data for demonstration> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>2>, random_state>=>42>)> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y, test_size>=>0.2>, random_state>=>42>)> |
>
>
Ved at bruge et splitforhold på 80-20 opretter algoritmen kunstige binære klassifikationsdata med 20 funktioner, opdeler dem i trænings- og testsæt og tildeler et tilfældigt frø for at sikre reproducerbarhed.
linkedlist i java
Træning af de forskellige modeller
Python3
# Train two different models> logistic_model>=> LogisticRegression(random_state>=>42>)> logistic_model.fit(X_train, y_train)> random_forest_model>=> RandomForestClassifier(n_estimators>=>100>, random_state>=>42>)> random_forest_model.fit(X_train, y_train)> |
>
>
Ved at bruge et fast tilfældigt seed for at sikre repeterbarhed initialiserer og træner metoden en logistisk regressionsmodel på træningssættet. På lignende måde bruger den træningsdataene og det samme tilfældige frø til at initialisere og træne en Random Forest-model med 100 træer.
Forudsigelser
Python3
# Generate predictions> y_pred_logistic>=> logistic_model.predict_proba(X_test)[:,>1>]> y_pred_rf>=> random_forest_model.predict_proba(X_test)[:,>1>]> |
>
>
Ved hjælp af testdata og en trænet Logistisk regression model, forudsiger koden den positive klasses sandsynlighed. På lignende måde, ved hjælp af testdata, bruger den den trænede Random Forest-model til at producere projicerede sandsynligheder for den positive klasse.
Oprettelse af en dataramme
Python3
# Create a DataFrame> test_df>=> pd.DataFrame(> >{>'True'>: y_test,>'Logistic'>: y_pred_logistic,>'RandomForest'>: y_pred_rf})> |
>
>
Ved at bruge testdataene opretter koden en DataFrame kaldet test_df med kolonner mærket True, Logistic og RandomForest, der tilføjer sande etiketter og forudsagte sandsynligheder fra Random Forest og Logistic Regression-modellerne.
Tegn ROC-kurven for modellerne
Python3
# Plot ROC curve for each model> plt.figure(figsize>=>(>7>,>5>))> for> model>in> [>'Logistic'>,>'RandomForest'>]:> >fpr, tpr, _>=> roc_curve(test_df[>'True'>], test_df[model])> >roc_auc>=> auc(fpr, tpr)> >plt.plot(fpr, tpr, label>=>f>'{model} (AUC = {roc_auc:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'r--'>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curves for Two Models'>)> plt.legend()> plt.show()> |
>
>
Produktion:

Koden genererer et plot med 8 x 6 tommer figurer. Den beregner AUC- og ROC-kurven for hver model (Random Forest and Logistic Regression), og plotter derefter ROC-kurven. Det ROC kurve for tilfældig gæt er også repræsenteret af en rød stiplet linje, og etiketter, en titel og en forklaring er indstillet til visualisering.
Hvordan bruger man ROC-AUC til en multi-klasse model?
For en multi-klasse indstilling, kan vi blot bruge en vs alle metode, og du vil have en ROC kurve for hver klasse. Lad os sige, at du har fire klasser A, B, C og D, så ville der være ROC-kurver og tilsvarende AUC-værdier for alle de fire klasser, dvs. når A vil være én klasse, og B, C og D kombineret ville være de andre klasse , på samme måde er B én klasse og A, C og D kombineret som andre klasse osv.
De generelle trin til brug af AUC-ROC i sammenhæng med en multiklasse klassifikationsmodel er:
En-mod-alle metode:
- For hver klasse i dit flerklasseproblem skal du behandle den som den positive klasse, mens du kombinerer alle andre klasser i den negative klasse.
- Træn den binære klassifikator for hver klasse mod resten af klasserne.
Beregn AUC-ROC for hver klasse:
- Her plotter vi ROC-kurven for den givne klasse mod resten.
- Plot ROC-kurverne for hver klasse på den samme graf. Hver kurve repræsenterer diskriminationspræstationen for modellen for en specifik klasse.
- Undersøg AUC-resultaterne for hver klasse. En højere AUC-score indikerer bedre diskrimination for den pågældende klasse.
Implementering af AUC-ROC i Multiclass Classification
Import af biblioteker
Python3
import> numpy as np> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.preprocessing>import> label_binarize> from> sklearn.multiclass>import> OneVsRestClassifier> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> from> itertools>import> cycle> |
>
>
Programmet opretter kunstige multiklasse-data, opdeler dem i trænings- og testsæt og bruger derefter One-vs-Restclassifier teknik til at træne klassifikatorer til både Random Forest og Logistic Regression. Til sidst plotter den de to modellers multiklasse ROC-kurver for at demonstrere, hvor godt de skelner mellem forskellige klasser.
Generering af data og opdeling
Python3
# Generate synthetic multiclass data> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>3>, n_informative>=>10>, random_state>=>42>)> # Binarize the labels> y_bin>=> label_binarize(y, classes>=>np.unique(y))> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y_bin, test_size>=>0.2>, random_state>=>42>)> |
>
>
Tre klasser og tyve funktioner udgør de syntetiske multiklassedata produceret af koden. Efter etiketbinarisering opdeles dataene i trænings- og testsæt i forholdet 80-20.
Træningsmodeller
Python3
# Train two different multiclass models> logistic_model>=> OneVsRestClassifier(LogisticRegression(random_state>=>42>))> logistic_model.fit(X_train, y_train)> rf_model>=> OneVsRestClassifier(> >RandomForestClassifier(n_estimators>=>100>, random_state>=>42>))> rf_model.fit(X_train, y_train)> |
>
>
Programmet træner to multiklasse modeller: en Random Forest model med 100 estimatorer og en logistisk regression model med One-vs-Rest tilgang . Med træningssættet af data er begge modeller monteret.
Plotning af AUC-ROC-kurven
Python3
# Compute ROC curve and ROC area for each class> fpr>=> dict>()> tpr>=> dict>()> roc_auc>=> dict>()> models>=> [logistic_model, rf_model]> plt.figure(figsize>=>(>6>,>5>))> colors>=> cycle([>'aqua'>,>'darkorange'>])> for> model, color>in> zip>(models, colors):> >for> i>in> range>(model.classes_.shape[>0>]):> >fpr[i], tpr[i], _>=> roc_curve(> >y_test[:, i], model.predict_proba(X_test)[:, i])> >roc_auc[i]>=> auc(fpr[i], tpr[i])> >plt.plot(fpr[i], tpr[i], color>=>color, lw>=>2>,> >label>=>f>'{model.__class__.__name__} - Class {i} (AUC = {roc_auc[i]:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'k--'>, lw>=>2>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'Multiclass ROC Curve with Logistic Regression and Random Forest'>)> plt.legend(loc>=>'lower right'>)> plt.show()> |
>
>
Produktion:

Random Forest og Logistic Regression modellernes ROC-kurver og AUC-score beregnes af koden for hver klasse. Multiklasse ROC-kurverne plottes derefter, viser diskriminationspræstationen for hver klasse og har en linje, der repræsenterer tilfældig gæt. Det resulterende plot tilbyder en grafisk evaluering af modellernes klassificeringsydelse.
Konklusion
I maskinlæring vurderes ydeevnen af binære klassifikationsmodeller ved hjælp af en afgørende metrik kaldet Area Under the Receiver Operating Characteristic (AUC-ROC). På tværs af forskellige beslutningstærskler viser det, hvordan sensitivitet og specificitet afvejes. Større forskelsbehandling mellem positive og negative tilfælde udvises typisk af en model med en højere AUC-score. Mens 0,5 angiver tilfældighed, repræsenterer 1 fejlfri ydeevne. Modeloptimering og -valg er hjulpet af den nyttige information, som AUC-ROC-kurven tilbyder om en models evne til at skelne mellem klasser. Når du arbejder med ubalancerede datasæt eller applikationer, hvor falske positive og falske negative har forskellige omkostninger, er det særligt nyttigt som en omfattende foranstaltning.
Ofte stillede spørgsmål til AUC ROC Curve i Machine Learning
1. Hvad er AUC-ROC kurven?
For forskellige klassificeringstærskler er afvejningen mellem sand positiv rate (sensitivitet) og falsk positiv rate (specificitet) grafisk repræsenteret af AUC-ROC-kurven.
2. Hvordan ser en perfekt AUC-ROC kurve ud?
Et areal på 1 på en ideel AUC-ROC kurve ville betyde, at modellen opnår optimal sensitivitet og specificitet ved alle tærskler.
3. Hvad betyder en AUC-værdi på 0,5?
AUC på 0,5 indikerer, at modellens ydeevne er sammenlignelig med tilfældig tilfældighed. Det tyder på manglende evne til at skelne.
4. Kan AUC-ROC bruges til multiklasse klassificering?
AUC-ROC anvendes ofte på problemer, der involverer binær klassificering. Variationer såsom makro-gennemsnit eller mikro-gennemsnit AUC kan tages i betragtning ved multiklasse klassificering.
5. Hvordan er AUC-ROC-kurven nyttig i modelevaluering?
En models evne til at skelne mellem klasser er omfattende opsummeret af AUC-ROC-kurven. Når du arbejder med ubalancerede datasæt, er det særligt nyttigt.