Uinformeret søgning er en klasse af generelle søgealgoritmer, som fungerer på brute force-måde. Uinformerede søgealgoritmer har ikke yderligere information om tilstand eller søgerum udover hvordan man krydser træet, så det kaldes også blindsøgning.
Følgende er de forskellige typer af uinformerede søgealgoritmer:
1. Bredde-først-søgning:
- Bredde-først-søgning er den mest almindelige søgestrategi til at krydse et træ eller en graf. Denne algoritme søger i bredden i et træ eller en graf, så det kaldes bredde-først søgning.
- BFS-algoritmen begynder at søge fra træets rodknude og udvider alle efterfølgerknudepunkter på det aktuelle niveau, før de flyttes til noder på næste niveau.
- Bredde-først-søgealgoritmen er et eksempel på en generel grafsøgealgoritme.
- Bredde-første søgning implementeret ved hjælp af FIFO kø datastruktur.
Fordele:
- BFS vil levere en løsning, hvis der findes en løsning.
- Hvis der er mere end én løsning til et givet problem, så vil BFS levere den minimale løsning, som kræver det mindste antal trin.
Ulemper:
- Det kræver masser af hukommelse, da hvert niveau i træet skal gemmes i hukommelsen for at udvide det næste niveau.
- BFS har brug for masser af tid, hvis løsningen er langt væk fra rodnoden.
Eksempel:
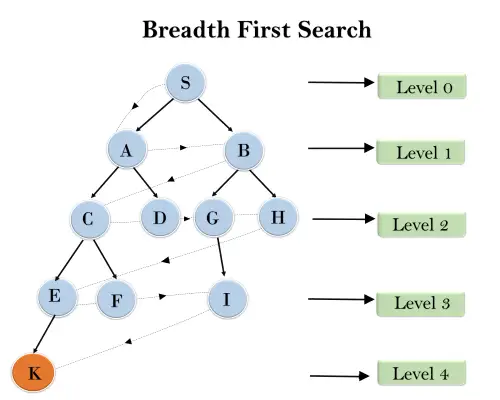
I nedenstående træstruktur har vi vist gennemkørslen af træet ved hjælp af BFS-algoritmen fra rodknudepunktet S til målknudepunktet K. BFS-søgealgoritmen krydser i lag, så den vil følge stien, som er vist med den stiplede pil, og gennemkørt vej vil være:
S---> A--->B---->C--->D---->G--->H--->E---->F---->I---->K
Tidskompleksitet: Tidskompleksiteten af BFS-algoritmen kan opnås ved antallet af knudepunkter, der krydses i BFS indtil den laveste knude. Hvor d = dybden af laveste opløsning og b er en knude i hver tilstand.
T(b) = 1+b2+b3+......+ bd= O (bd)
edith mack hirsch
Rumkompleksitet: Rumkompleksiteten af BFS-algoritmen er givet af hukommelsesstørrelsen på grænsen, som er O(bd).
Fuldstændighed: BFS er fuldført, hvilket betyder, at hvis den laveste målknude er i en eller anden endelig dybde, så vil BFS finde en løsning.
Optimalitet: BFS er optimal, hvis stiomkostninger er en ikke-aftagende funktion af knudepunktets dybde.
2. Dybde-først søgning
- Dybde-først søgning er en rekursiv algoritme til at krydse et træ eller en grafdatastruktur.
- Det kaldes dybde-først-søgningen, fordi det starter fra rodknudepunktet og følger hver sti til dens største dybdeknude, før den bevæger sig til den næste sti.
- DFS bruger en stakdatastruktur til implementeringen.
- Processen med DFS-algoritmen ligner BFS-algoritmen.
Bemærk: Backtracking er en algoritmeteknik til at finde alle mulige løsninger ved hjælp af rekursion.
Fordel:
- DFS kræver meget mindre hukommelse, da den kun behøver at gemme en stak af noderne på stien fra rodknudepunktet til den aktuelle knude.
- Det tager kortere tid at nå til målknudepunktet end BFS-algoritmen (hvis den krydser den rigtige vej).
Ulempe:
- Der er mulighed for, at mange stater bliver ved med at opstå igen, og der er ingen garanti for at finde løsningen.
- DFS-algoritmen går til dybtgående søgning, og på et tidspunkt kan den gå til den uendelige løkke.
Eksempel:
I nedenstående søgetræ har vi vist flowet af dybde-først søgning, og det vil følge rækkefølgen som:
Rodknude--->Venstre knude ----> højre knude.
Den vil begynde at søge fra rodknudepunktet S og krydse A, derefter B, derefter D og E, efter at have krydset E, vil den spore træet tilbage, da E ikke har nogen anden efterfølger, og målknuden stadig ikke findes. Efter tilbagesporing vil den krydse node C og derefter G, og her vil den afslutte, da den fandt målknudepunktet.

Fuldstændighed: DFS-søgealgoritmen er komplet inden for finite state space, da den vil udvide hver node inden for et begrænset søgetræ.
Tidskompleksitet: Tidskompleksiteten af DFS vil svare til den node, som algoritmen krydser. Det er givet af:
T(n)= 1+ n2+ n3+.........+ nm=O(nm)
Hvor, m = maksimal dybde af enhver knude, og denne kan være meget større end d (Lyneste løsningsdybde)
Rumkompleksitet: DFS-algoritmen behøver kun at gemme en enkelt sti fra rodknuden, derfor er pladskompleksiteten af DFS ækvivalent med størrelsen af frynsesættet, hvilket er Om .
Optimal: DFS-søgealgoritmen er ikke-optimal, da den kan generere et stort antal trin eller høje omkostninger for at nå til målknuden.
3. Dybdebegrænset søgealgoritme:
En dybdebegrænset søgealgoritme svarer til dybde-først søgning med en forudbestemt grænse. Dybdebegrænset søgning kan løse ulempen ved den uendelige vej i Dybde-først-søgningen. I denne algoritme vil knudepunktet ved dybdegrænsen behandle, da det ikke har nogen efterfølgende knudepunkter yderligere.
Dybdebegrænset søgning kan afsluttes med to fejlbetingelser:
- Standardfejlværdi: Det indikerer, at problemet ikke har nogen løsning.
- Cutoff-fejlværdi: Den definerer ingen løsning på problemet inden for en given dybdegrænse.
Fordele:
Dybdebegrænset søgning er hukommelseseffektiv.
Ulemper:
- Dybdebegrænset søgning har også en ulempe ved ufuldstændighed.
- Det er måske ikke optimalt, hvis problemet har mere end én løsning.
Eksempel:

Fuldstændighed: DLS-søgealgoritmen er komplet, hvis løsningen er over dybdegrænsen.
Tidskompleksitet: Tidskompleksiteten af DLS-algoritmen er O(bℓ) .
forskel mellem array og arraylist
Rumkompleksitet: Rumkompleksiteten af DLS-algoritmen er O (b�ℓ) .
Optimal: Dybdebegrænset søgning kan ses som et specialtilfælde af DFS, og det er heller ikke optimalt, selvom ℓ>d.
4. Ensartet prissøgningsalgoritme:
Ensartet prissøgning er en søgealgoritme, der bruges til at krydse et vægtet træ eller en graf. Denne algoritme kommer i spil, når en anden pris er tilgængelig for hver kant. Det primære mål med søgningen efter ensartede omkostninger er at finde en vej til den målknude, som har den laveste kumulative omkostning. Ensartet omkostningssøgning udvider noder i henhold til deres stiomkostninger fra rodknuden. Det kan bruges til at løse enhver graf/træ, hvor den optimale omkostning er efterspurgt. En ensartet prissøgningsalgoritme implementeres af prioritetskøen. Det giver maksimal prioritet til de laveste kumulative omkostninger. Ensartet omkostningssøgning svarer til BFS-algoritmen, hvis stiomkostningerne for alle kanter er de samme.
Fordele:
- Ensartet omkostningssøgning er optimal, fordi stien med de mindste omkostninger i hver stat vælges.
Ulemper:
- Den er ligeglad med antallet af trin, der er involveret i søgningen og bekymrer sig kun om stiomkostninger. På grund af dette kan denne algoritme sidde fast i en uendelig løkke.
Eksempel:

Fuldstændighed:
Ensartet omkostningssøgning er færdig, som hvis der er en løsning, vil UCS finde den.
Tidskompleksitet:
Lad C* er Omkostningerne ved den optimale løsning , og e er hvert trin for at komme tættere på målknuden. Så er antallet af trin = C*/ε+1. Her har vi taget +1, da vi starter fra tilstand 0 og slutter til C*/ε.
Derfor er det værst tænkelige tidskompleksitet ved Uniform-omkostningssøgning O(b1 + [C*/e])/ .
Rumkompleksitet:
Den samme logik er for rumkompleksitet, så den værste pladskompleksitet ved Uniform-cost-søgning er O(b1 + [C*/e]) .
Optimal:
Ensartet omkostningssøgning er altid optimal, da den kun vælger en sti med den laveste stiomkostning.
5. Iterativ uddybning-først-søgning:
Den iterative uddybningsalgoritme er en kombination af DFS- og BFS-algoritmer. Denne søgealgoritme finder den bedste dybdegrænse og gør det ved gradvist at øge grænsen, indtil et mål er fundet.
10 af 40
Denne algoritme udfører dybde-først-søgning op til en vis 'dybdegrænse', og den bliver ved med at øge dybdegrænsen efter hver iteration, indtil målknuden er fundet.
Denne søgealgoritme kombinerer fordelene ved Breadth-first-søgnings hurtige søgning og dybde-først-søgnings hukommelseseffektivitet.
Den iterative søgealgoritme er nyttig, uinformeret søgning, når søgerummet er stort, og dybden af målknudepunktet er ukendt.
Fordele:
- Den kombinerer fordelene ved BFS- og DFS-søgealgoritmer i form af hurtig søgning og hukommelseseffektivitet.
Ulemper:
- Den største ulempe ved IDDFS er, at den gentager alt arbejdet i den foregående fase.
Eksempel:
Følgende træstruktur viser den iterative uddybende dybde-første søgning. IDDFS-algoritmen udfører forskellige iterationer, indtil den ikke finder målknuden. Iterationen udført af algoritmen er givet som:

1. iteration-----> A
2. iteration----> A, B, C
3. iteration------>A, B, D, E, C, F, G
4. iteration ------>A, B, D, H, I, E, C, F, K, G
I den fjerde iteration vil algoritmen finde målknuden.
Fuldstændighed:
Denne algoritme er komplet, hvis forgreningsfaktoren er endelig.
Tidskompleksitet:
Lad os antage, at b er forgreningsfaktoren, og dybden er d, så er tidskompleksiteten i det værste tilfælde O(bd) .
Rumkompleksitet:
Rumkompleksiteten af IDDFS vil være O(bd) .
Optimal:
IDDFS-algoritmen er optimal, hvis stiomkostningerne er en ikke-aftagende funktion af knudepunktets dybde.
6. Tovejs søgealgoritme:
Bidirektionel søgealgoritme kører to samtidige søgninger, den ene starttilstand kaldet fremadsøgning og en anden fra målknudepunktet kaldet bagudsøgning for at finde målknuden. Tovejssøgning erstatter en enkelt søgegraf med to små undergrafer, hvor den ene starter søgningen fra et indledende toppunkt og den anden starter fra målets toppunkt. Søgningen stopper, når disse to grafer skærer hinanden.
overvåget maskinlæring
Tovejssøgning kan bruge søgeteknikker som BFS, DFS, DLS osv.
Fordele:
- Tovejssøgning er hurtig.
- Tovejssøgning kræver mindre hukommelse
Ulemper:
- Implementering af det tovejs søgetræ er vanskelig.
Eksempel:
I nedenstående søgetræ anvendes tovejs søgealgoritme. Denne algoritme opdeler en graf/træ i to undergrafer. Den begynder at krydse fra knude 1 i fremadgående retning og starter fra målknude 16 i baglæns retning.
Algoritmen afsluttes ved node 9, hvor to søgninger mødes.

Fuldstændighed: Tovejssøgning er fuldført, hvis vi bruger BFS i begge søgninger.
Tidskompleksitet: Tidskompleksiteten af tovejssøgning ved hjælp af BFS er O(bd) .
Rumkompleksitet: Rumkompleksiteten af tovejssøgning er O(bd) .
Optimal: Tovejssøgning er optimal.