Machine learning er grenen af Kunstig intelligens der fokuserer på at udvikle modeller og algoritmer, der lader computere lære af data og forbedre sig fra tidligere erfaringer uden at være eksplicit programmeret til hver opgave. Med enkle ord lærer ML systemerne at tænke og forstå som mennesker ved at lære af dataene.
I denne artikel vil vi udforske de forskellige typer af maskinlæringsalgoritmer som er vigtige for fremtidige krav. Maskinelæring er generelt et træningssystem til at lære af tidligere erfaringer og forbedre præstationen over tid. Maskinelæring hjælper med at forudsige enorme mængder data. Det hjælper med at levere hurtige og præcise resultater for at få rentable muligheder.
Typer af maskinlæring
Der er flere typer maskinlæring, hver med særlige karakteristika og applikationer. Nogle af hovedtyperne af maskinlæringsalgoritmer er som følger:
- Supervised Machine Learning
- Uovervåget maskinlæring
- Semi-Supervised Machine Learning
- Forstærkende læring
Typer af maskinlæring
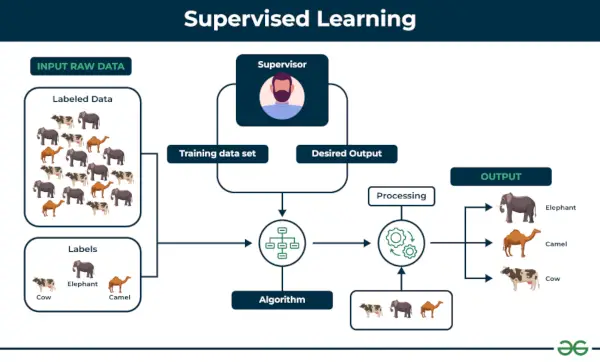
1. Supervised Machine Learning
Superviseret læring defineres som når en model bliver trænet på en Mærket Datasæt . Mærkede datasæt har både input- og outputparametre. I Superviseret læring Algoritmer lærer at kortlægge punkter mellem input og korrekte output. Det har både trænings- og valideringsdatasæt mærket.
Superviseret læring
Lad os forstå det ved hjælp af et eksempel.
Eksempel: Overvej et scenarie, hvor du skal bygge en billedklassificering for at skelne mellem katte og hunde. Hvis du tilfører datasættene af hunde og katte mærkede billeder til algoritmen, vil maskinen lære at klassificere mellem en hund eller en kat ud fra disse mærkede billeder. Når vi indtaster nye hunde- eller kattebilleder, som den aldrig har set før, vil den bruge de indlærte algoritmer og forudsige, om det er en hund eller en kat. Sådan her overvåget læring virker, og dette er især en billedklassificering.
Der er to hovedkategorier af superviseret læring, der er nævnt nedenfor:
- Klassifikation
- Regression
Klassifikation
Klassifikation handler om at forudsige kategorisk målvariabler, som repræsenterer diskrete klasser eller etiketter. For eksempel at klassificere e-mails som spam eller ej spam eller forudsige, om en patient har en høj risiko for hjertesygdom. Klassifikationsalgoritmer lærer at kortlægge inputfunktionerne til en af de foruddefinerede klasser.
Her er nogle klassifikationsalgoritmer:
- Logistisk regression
- Support Vector Machine
- Tilfældig Skov
- Beslutningstræ
- K-Nærmeste Naboer (KNN)
- Naiv Bayes
Regression
Regression beskæftiger sig derimod med at forudsige sammenhængende målvariabler, som repræsenterer numeriske værdier. For eksempel at forudsige prisen på et hus baseret på dets størrelse, beliggenhed og faciliteter, eller forudsige salget af et produkt. Regressionsalgoritmer lærer at kortlægge inputfunktionerne til en kontinuerlig numerisk værdi.
Her er nogle regressionsalgoritmer:
- Lineær regression
- Polynomisk regression
- Ridge regression
- Lasso regression
- Beslutningstræ
- Tilfældig Skov
Fordele ved Supervised Machine Learning
- Superviseret læring modeller kan have høj nøjagtighed, som de trænes på mærkede data .
- Beslutningsprocessen i superviserede læringsmodeller er ofte fortolkelig.
- Det kan ofte bruges i præ-trænede modeller, hvilket sparer tid og ressourcer, når man udvikler nye modeller fra bunden.
Ulemper ved Supervised Machine Learning
- Det har begrænsninger i at kende mønstre og kan kæmpe med usynlige eller uventede mønstre, som ikke er til stede i træningsdataene.
- Det kan være tidskrævende og dyrt, da det er afhængigt af mærket kun data.
- Det kan føre til dårlige generaliseringer baseret på nye data.
Anvendelser af superviseret læring
Superviseret læring bruges i en lang række applikationer, herunder:
- Billedklassificering : Identificer objekter, ansigter og andre funktioner i billeder.
- Naturlig sprogbehandling: Uddrag information fra tekst, såsom følelser, entiteter og relationer.
- Tale genkendelse : Konverter talesprog til tekst.
- Anbefalingssystemer : Lav personlige anbefalinger til brugere.
- Forudsigende analyse : Forudsige resultater, såsom salg, kundeafgang og aktiekurser.
- Medicinsk diagnose : Opdag sygdomme og andre medicinske tilstande.
- Opdagelse af svindel : Identificer svigagtige transaktioner.
- Autonome køretøjer : Genkend og reagere på genstande i miljøet.
- Registrering af spam via e-mail : Klassificer e-mails som spam eller ikke spam.
- Kvalitetskontrol i produktionen : Undersøg produkter for defekter.
- Kreditvurdering : Vurder risikoen for, at en låntager misligholder et lån.
- Spil : Genkend karakterer, analyser spilleradfærd og opret NPC'er.
- Kunde support : Automatiser kundesupportopgaver.
- Vejrudsigt : Lav forudsigelser for temperatur, nedbør og andre meteorologiske parametre.
- Sportsanalyse : Analyser spillerens præstation, lav spilforudsigelser og optimer strategier.
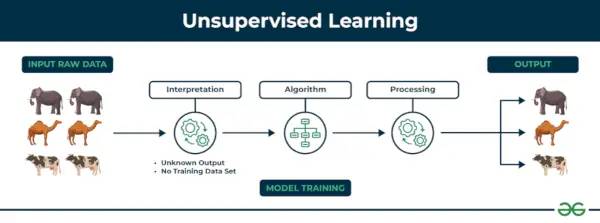
2. Uovervåget maskinlæring
Uovervåget læring Uovervåget læring er en type maskinlæringsteknik, hvor en algoritme opdager mønstre og relationer ved hjælp af umærkede data. I modsætning til overvåget læring involverer uovervåget læring ikke at forsyne algoritmen med mærkede måloutput. Det primære mål med uovervåget læring er ofte at opdage skjulte mønstre, ligheder eller klynger i dataene, som derefter kan bruges til forskellige formål, såsom dataudforskning, visualisering, dimensionalitetsreduktion og meget mere.
Uovervåget læring
Lad os forstå det ved hjælp af et eksempel.
Eksempel: Overvej, at du har et datasæt, der indeholder oplysninger om de køb, du har foretaget i butikken. Gennem clustering kan algoritmen gruppere den samme købsadfærd blandt dig og andre kunder, hvilket afslører potentielle kunder uden foruddefinerede etiketter. Denne type information kan hjælpe virksomheder med at få målkunder samt identificere outliers.
Der er to hovedkategorier af uovervåget læring, der er nævnt nedenfor:
- Klynger
- Foreningen
Klynger
Klynger er processen med at gruppere datapunkter i klynger baseret på deres lighed. Denne teknik er nyttig til at identificere mønstre og relationer i data uden behov for mærkede eksempler.
Her er nogle klyngealgoritmer:
- K-Means Clustering-algoritme
- Mean-shift algoritme
- DBSCAN-algoritme
- Hovedkomponentanalyse
- Uafhængig komponentanalyse
Foreningen
Association regel lære ing er en teknik til at opdage relationer mellem elementer i et datasæt. Det identificerer regler, der angiver tilstedeværelsen af et element, antyder tilstedeværelsen af et andet element med en specifik sandsynlighed.
Her er nogle algoritmer til indlæring af tilknytningsregler:
- Apriori algoritme
- Glød
- FP-vækst-algoritme
Fordele ved uovervåget maskinlæring
- Det hjælper med at opdage skjulte mønstre og forskellige relationer mellem dataene.
- Anvendes til opgaver som f.eks kundesegmentering, opdagelse af anomalier, og dataudforskning .
- Det kræver ikke mærkede data og reducerer indsatsen for datamærkning.
Ulemper ved uovervåget maskinlæring
- Uden at bruge etiketter kan det være svært at forudsige kvaliteten af modellens output.
- Klyngefortolkning er muligvis ikke klar og har muligvis ikke meningsfulde fortolkninger.
- Den har teknikker som f.eks autoencodere og dimensionsreduktion der kan bruges til at udtrække meningsfulde funktioner fra rådata.
Anvendelser af uovervåget læring
Her er nogle almindelige anvendelser af uovervåget læring:
- Klynger : Gruppér lignende datapunkter i klynger.
- Anomali detektion : Identificer outliers eller anomalier i data.
- Dimensionalitetsreduktion : Reducer dimensionaliteten af data, samtidig med at dens væsentlige information bevares.
- Anbefalingssystemer : Foreslå produkter, film eller indhold til brugere baseret på deres historiske adfærd eller præferencer.
- Emnemodellering : Opdag latente emner i en samling af dokumenter.
- Densitetsvurdering : Estimer sandsynlighedstæthedsfunktionen for data.
- Billed- og videokomprimering : Reducer mængden af krævet lagerplads til multimedieindhold.
- Dataforbehandling : Hjælp til dataforbehandlingsopgaver såsom datarensning, imputering af manglende værdier og dataskalering.
- Analyse af markedskurven : Opdag associationer mellem produkter.
- Genomisk dataanalyse : Identificer mønstre eller gruppegener med lignende ekspressionsprofiler.
- Billedsegmentering : Segmentér billeder i meningsfulde områder.
- Fællesskabsdetektion i sociale netværk : Identificer fællesskaber eller grupper af individer med lignende interesser eller forbindelser.
- Kundeadfærdsanalyse : Afdække mønstre og indsigt for bedre markedsføring og produktanbefalinger.
- Indholdsanbefaling : Klassificer og tag indhold for at gøre det nemmere at anbefale lignende varer til brugere.
- Udforskende dataanalyse (EDA) : Udforsk data og få indsigt, før du definerer specifikke opgaver.
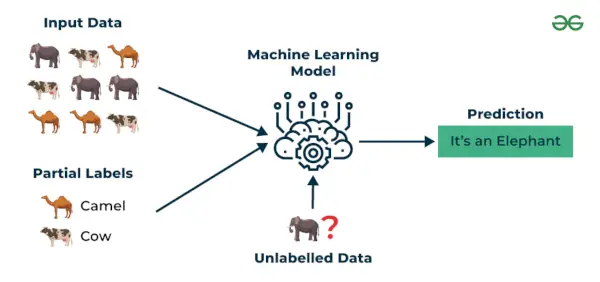
3. Semi-Supervised Learning
Semi-superviseret læring er en maskinlæringsalgoritme, der fungerer mellem overvåget og uden opsyn læring, så den bruger begge dele mærket og umærket data. Det er især nyttigt, når det er dyrt, tidskrævende eller ressourcekrævende at få mærkede data. Denne tilgang er nyttig, når datasættet er dyrt og tidskrævende. Semi-superviseret læring vælges, når mærkede data kræver færdigheder og relevante ressourcer for at træne eller lære af dem.
Vi bruger disse teknikker, når vi har at gøre med data, der er en lille smule mærket, og resten store del af det er umærket. Vi kan bruge de uovervågede teknikker til at forudsige etiketter og derefter føre disse etiketter til overvågede teknikker. Denne teknik er mest anvendelig i tilfælde af billeddatasæt, hvor alle billeder normalt ikke er mærket.
Semi-superviseret læring
Lad os forstå det ved hjælp af et eksempel.
Eksempel : Overvej, at vi bygger en sprogoversættelsesmodel, da det kan være ressourcekrævende at have mærkede oversættelser for hvert sætningspar. Det giver modellerne mulighed for at lære af mærkede og umærkede sætningspar, hvilket gør dem mere nøjagtige. Denne teknik har ført til betydelige forbedringer i kvaliteten af maskinoversættelsestjenester.
Typer af semi-superviserede læringsmetoder
Der er en række forskellige semi-superviserede læringsmetoder, hver med sine egne karakteristika. Nogle af de mest almindelige omfatter:
- Grafbaseret semi-superviseret læring: Denne tilgang bruger en graf til at repræsentere relationerne mellem datapunkterne. Grafen bruges derefter til at udbrede etiketter fra de mærkede datapunkter til de umærkede datapunkter.
- Etiketudbredelse: Denne tilgang udbreder iterativt etiketter fra de mærkede datapunkter til de umærkede datapunkter, baseret på lighederne mellem datapunkterne.
- Samtræning: Denne tilgang træner to forskellige maskinlæringsmodeller på forskellige delmængder af de umærkede data. De to modeller bruges derefter til at mærke hinandens forudsigelser.
- Selvtræning: Denne tilgang træner en maskinlæringsmodel på de mærkede data og bruger derefter modellen til at forudsige etiketter for de umærkede data. Modellen genoptrænes derefter på de mærkede data og de forudsagte mærker for de umærkede data.
- Generative adversarielle netværk (GAN'er) : GAN'er er en type deep learning-algoritme, der kan bruges til at generere syntetiske data. GAN'er kan bruges til at generere umærkede data til semi-overvåget læring ved at træne to neurale netværk, en generator og en diskriminator.
Fordele ved Semi-Supervised Machine Learning
- Det fører til bedre generalisering i forhold til overvåget læring, da det tager både mærkede og umærkede data.
- Kan anvendes på en bred vifte af data.
Ulemper ved Semi-Supervised Machine Learning
- Semi-overvåget metoder kan være mere komplekse at implementere sammenlignet med andre tilgange.
- Det kræver stadig noget mærkede data som måske ikke altid er tilgængelige eller nemme at få.
- De umærkede data kan påvirke modellens ydeevne tilsvarende.
Anvendelser af semi-overvåget læring
Her er nogle almindelige anvendelser af semi-overvåget læring:
- Billedklassificering og objektgenkendelse : Forbedre nøjagtigheden af modeller ved at kombinere et lille sæt mærkede billeder med et større sæt umærkede billeder.
- Natural Language Processing (NLP) : Forbedre ydeevnen af sprogmodeller og klassifikatorer ved at kombinere et lille sæt mærkede tekstdata med en stor mængde umærket tekst.
- Tale genkendelse: Forbedre nøjagtigheden af talegenkendelse ved at udnytte en begrænset mængde transskriberede taledata og et mere omfattende sæt umærket lyd.
- Anbefalingssystemer : Forbedre nøjagtigheden af personlige anbefalinger ved at supplere et sparsomt sæt interaktioner mellem brugerelementer (mærkede data) med et væld af umærkede brugeradfærdsdata.
- Sundhedspleje og medicinsk billeddannelse : Forbedre medicinsk billedanalyse ved at bruge et lille sæt mærkede medicinske billeder sammen med et større sæt umærkede billeder.
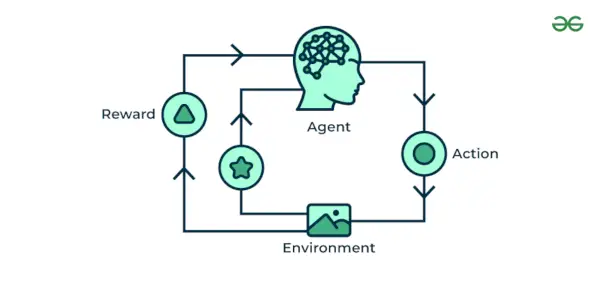
4. Maskinlæring for forstærkning
Forstærkende maskinlæring Algoritme er en læringsmetode, der interagerer med omgivelserne ved at producere handlinger og opdage fejl. Prøv, fejl og forsinkelse er de mest relevante karakteristika ved forstærkningslæring. I denne teknik fortsætter modellen med at øge sin præstation ved at bruge Reward Feedback til at lære adfærden eller mønsteret. Disse algoritmer er specifikke for et bestemt problem, f.eks. Google Self Driving car, AlphaGo, hvor en bot konkurrerer med mennesker og endda sig selv for at få bedre og bedre performere i Go Game. Hver gang vi indlæser data, lærer de og tilføjer dataene til deres viden, hvilket er træningsdata. Så jo mere det lærer, jo bedre bliver det trænet og dermed oplevet.
Her er nogle af de mest almindelige forstærkningslæringsalgoritmer:
- Q-læring: Q-learning er en modelfri RL-algoritme, der lærer en Q-funktion, som kortlægger tilstande til handlinger. Q-funktionen estimerer den forventede belønning for at udføre en bestemt handling i en given tilstand.
- SARSA (State-Action-Reward-State-Action): SARSA er en anden modelfri RL-algoritme, der lærer en Q-funktion. Men i modsætning til Q-learning opdaterer SARSA Q-funktionen for den handling, der faktisk blev foretaget, snarere end den optimale handling.
- Dyb Q-læring : Deep Q-learning er en kombination af Q-learning og deep learning. Deep Q-learning bruger et neuralt netværk til at repræsentere Q-funktionen, som giver den mulighed for at lære komplekse forhold mellem tilstande og handlinger.
Maskinlæring for forstærkning
Lad os forstå det ved hjælp af eksempler.
Eksempel: Overvej at du træner en AI agent til at spille et spil som skak. Agenten udforsker forskellige bevægelser og modtager positiv eller negativ feedback baseret på resultatet. Reinforcement Learning finder også applikationer, hvor de lærer at udføre opgaver ved at interagere med deres omgivelser.
Typer af forstærkningsmaskinelæring
Der er to hovedtyper af forstærkende læring:
Positiv forstærkning
- Belønner agenten for at udføre en ønsket handling.
- Opmuntrer agenten til at gentage adfærden.
- Eksempler: At give en godbid til en hund for at sidde, give et point i et spil for et korrekt svar.
Negativ forstærkning
10 af 40
- Fjerner en uønsket stimulus for at fremme en ønsket adfærd.
- Afskrækker agenten fra at gentage adfærden.
- Eksempler: Deaktivering af en høj summer, når der trykkes på et håndtag, undgå en straf ved at fuldføre en opgave.
Fordele ved forstærkningsmaskineindlæring
- Den har autonom beslutningstagning, der er velegnet til opgaver, og som kan lære at træffe en række beslutninger, såsom robotteknologi og spil.
- Denne teknik foretrækkes for at opnå langsigtede resultater, som er meget svære at opnå.
- Det bruges til at løse komplekse problemer, som ikke kan løses med konventionelle teknikker.
Ulemper ved Reinforcement Machine Learning
- Træningsforstærkning Læringsmidler kan være beregningsmæssigt dyre og tidskrævende.
- Forstærkende læring er ikke at foretrække frem for at løse simple problemer.
- Det kræver en masse data og en masse beregninger, hvilket gør det upraktisk og dyrt.
Anvendelser af forstærkningsmaskinelæring
Her er nogle anvendelser af forstærkende læring:
- Spil : RL kan lære agenter at spille spil, selv komplekse.
- Robotik : RL kan lære robotter at udføre opgaver autonomt.
- Autonome køretøjer : RL kan hjælpe selvkørende biler med at navigere og træffe beslutninger.
- Anbefalingssystemer : RL kan forbedre anbefalingsalgoritmer ved at lære brugerpræferencer.
- Sundhedspleje : RL kan bruges til at optimere behandlingsplaner og lægemiddelopdagelse.
- Natural Language Processing (NLP) : RL kan bruges i dialogsystemer og chatbots.
- Finansiering og handel : RL kan bruges til algoritmisk handel.
- Supply Chain og Lagerstyring : RL kan bruges til at optimere forsyningskædens drift.
- Energiledelse : RL kan bruges til at optimere energiforbruget.
- AI spil : RL kan bruges til at skabe mere intelligente og adaptive NPC'er i videospil.
- Adaptive personlige assistenter : RL kan bruges til at forbedre personlige assistenter.
- Virtual Reality (VR) og Augmented Reality (AR): RL kan bruges til at skabe fordybende og interaktive oplevelser.
- Industriel kontrol : RL kan bruges til at optimere industrielle processer.
- Uddannelse : RL kan bruges til at skabe adaptive læringssystemer.
- Landbrug : RL kan bruges til at optimere landbrugets drift.
Skal tjekke, vores detaljerede artikel om : Machine Learning Algoritmer
Konklusion
Som konklusion tjener hver type maskinlæring sit eget formål og bidrager til den overordnede rolle i udviklingen af forbedrede dataforudsigelseskapaciteter, og den har potentialet til at ændre forskellige industrier som f.eks. Datavidenskab . Det hjælper med at håndtere massiv dataproduktion og styring af datasættene.
Typer af maskinlæring – ofte stillede spørgsmål
1. Hvilke udfordringer står over for i superviseret læring?
Nogle af de udfordringer, man står over for i superviseret læring, omfatter hovedsageligt håndtering af klasseubalancer, mærkede data af høj kvalitet og undgåelse af overfitting, hvor modeller klarer sig dårligt på realtidsdata.
2. Hvor kan vi anvende superviseret læring?
Overvåget læring bruges almindeligvis til opgaver som at analysere spam-e-mails, billedgenkendelse og følelsesanalyse.
3. Hvordan ser fremtidens udsigter for maskinlæring ud?
Maskinlæring som fremtidsudsigt kan fungere inden for områder som vejr- eller klimaanalyse, sundhedssystemer og autonom modellering.
4. Hvad er de forskellige typer maskinlæring?
Der er tre hovedtyper af maskinlæring:
- Superviseret læring
- Uovervåget læring
- Forstærkende læring
5. Hvad er de mest almindelige maskinlæringsalgoritmer?
Nogle af de mest almindelige maskinlæringsalgoritmer inkluderer:
- Lineær regression
- Logistisk regression
- Understøtte vektormaskiner (SVM'er)
- K-nærmeste naboer (KNN)
- Beslutningstræer
- Tilfældige skove
- Kunstige neurale netværk