En markør i SQL Server er en d atabase-objekt, der giver os mulighed for at hente hver række ad gangen og manipulere dens data . En markør er ikke andet end en pegepind til en række. Det bruges altid sammen med en SELECT-sætning. Det er normalt en samling af SQL logik, der går gennem et forudbestemt antal rækker én efter én. En simpel illustration af markøren er, når vi har en omfattende database over arbejdernes optegnelser og ønsker at beregne hver enkelt arbejders løn efter fradrag af skatter og orlov.
SQL-serveren markørens formål er at opdatere dataene række for række, ændre dem eller udføre beregninger, der ikke er mulige, når vi henter alle poster på én gang . Det er også nyttigt til at udføre administrative opgaver som SQL Server-databasesikkerhedskopier i sekventiel rækkefølge. Markører bruges hovedsageligt i udviklings-, DBA- og ETL-processerne.
Denne artikel forklarer alt om SQL Server-markøren, såsom markørens livscyklus, hvorfor og hvornår markøren bruges, hvordan man implementerer markører, dens begrænsninger, og hvordan vi kan erstatte en markør.
Markørens livscyklus
Vi kan beskrive en markørs livscyklus ind i fem forskellige sektioner som følger:
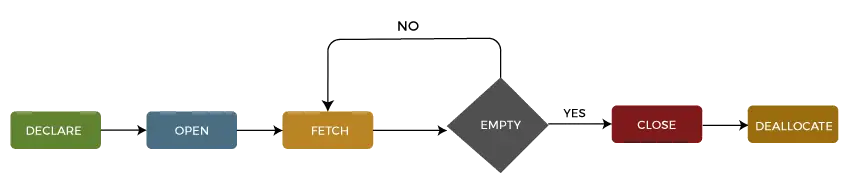
1: Erklær markør
Det første trin er at erklære markøren ved hjælp af nedenstående SQL-sætning:
liste node i java
DECLARE cursor_name CURSOR FOR select_statement;
Vi kan erklære en markør ved at angive dens navn med datatypen CURSOR efter nøgleordet DECLARE. Derefter vil vi skrive SELECT-sætningen, der definerer output for markøren.
2: Åbn markøren
Det er et andet trin, hvor vi åbner markøren for at gemme data hentet fra resultatsættet. Vi kan gøre dette ved at bruge nedenstående SQL-sætning:
OPEN cursor_name;
3: Hent markør
Det er et tredje trin, hvor rækker kan hentes én efter én eller i en blok for at udføre datamanipulation som at indsætte, opdatere og slette handlinger på den aktuelt aktive række i markøren. Vi kan gøre dette ved at bruge nedenstående SQL-sætning:
FETCH NEXT FROM cursor INTO variable_list;
Vi kan også bruge @@FETCHSTATUS funktion i SQL Server for at få status for den seneste FETCH-sætningsmarkør, der blev udført mod markøren. Det HENT sætningen var vellykket, når @@FETCHSTATUS giver nul output. Det MENS statement kan bruges til at hente alle poster fra markøren. Følgende kode forklarer det mere tydeligt:
WHILE @@FETCH_STATUS = 0 BEGIN FETCH NEXT FROM cursor_name; END;
4: Luk markøren
Det er et fjerde trin, hvor markøren skal lukkes, når vi er færdige med at arbejde med en markør. Vi kan gøre dette ved at bruge nedenstående SQL-sætning:
CLOSE cursor_name;
5: Tildel markør
Det er det femte og sidste trin, hvor vi sletter markørdefinitionen og frigiver alle systemressourcer forbundet med markøren. Vi kan gøre dette ved at bruge nedenstående SQL-sætning:
DEALLOCATE cursor_name;
Brug af SQL Server Cursor
Vi ved, at relationelle databasestyringssystemer, inklusive SQL Server, er fremragende til at håndtere data på et sæt rækker kaldet resultatsæt. For eksempel , vi har et bord produkttabel der indeholder produktbeskrivelserne. Hvis vi ønsker at opdatere pris af produktet, derefter nedenstående ' OPDATERING' forespørgslen vil opdatere alle poster, der matcher betingelsen i ' HVOR' klausul:
UPDATE product_table SET unit_price = 100 WHERE product_id = 105;
Nogle gange skal applikationen behandle rækkerne på en enkelt måde, dvs. række for række i stedet for hele resultatet på én gang. Vi kan gøre denne proces ved at bruge markører i SQL Server. Før du bruger markøren, skal vi vide, at markører er meget dårlige i ydeevne, så den bør altid kun bruges, når der ikke er nogen anden mulighed end markøren.
Markøren bruger den samme teknik, som vi bruger loops som FOREACH, FOR, WHILE, DO WHILE til at iterere et objekt ad gangen i alle programmeringssprog. Derfor kunne det vælges, fordi det anvender samme logik som programmeringssprogets looping-proces.
Typer af markører i SQL Server
Følgende er de forskellige typer markører i SQL Server, der er anført nedenfor:
- Statiske markører
- Dynamiske markører
- Kun fremad-markører
- Keyset Cursorer

Statiske markører
Resultatsættet, der vises af den statiske markør, er altid det samme, som da markøren blev åbnet første gang. Da den statiske markør vil gemme resultatet i tempdb , det er de altid Læs kun . Vi kan bruge den statiske markør til at flytte både frem og tilbage. I modsætning til andre markører er den langsommere og bruger mere hukommelse. Som et resultat kan vi kun bruge det, når det er nødvendigt at rulle, og andre markører ikke er egnede.
Denne markør viser rækker, der blev fjernet fra databasen, efter den blev åbnet. En statisk markør repræsenterer ikke nogen INSERT-, UPDATE- eller DELETE-handlinger (medmindre markøren er lukket og genåbnet).
Dynamiske markører
De dynamiske markører er modsatte af de statiske markører, der giver os mulighed for at udføre dataopdatering, sletning og indsættelse, mens markøren er åben. det er kan rulle som standard . Den kan registrere alle ændringer, der er foretaget i rækkerne, rækkefølgen og værdierne i resultatsættet, uanset om ændringerne sker inde i markøren eller uden for markøren. Uden for markøren kan vi ikke se opdateringerne, før de er begået.
Kun fremad-markører
Det er standard og hurtigste markørtype blandt alle markører. Det kaldes en kun fremad-markør, fordi det bevæger sig kun fremad gennem resultatsættet . Denne markør understøtter ikke rulning. Den kan kun hente rækker fra begyndelsen til slutningen af resultatsættet. Det giver os mulighed for at udføre indsættelse, opdatering og sletning. Her er effekten af indsættelse, opdatering og sletning udført af brugeren, der påvirker rækker i resultatsættet, synlig, når rækkerne hentes fra markøren. Når rækken blev hentet, kan vi ikke se ændringerne i rækker gennem markøren.
De fremadrettede markører er tre kategoriseret i tre typer:
- Forward_Only Keyset
- Forward_Only Static
- Spol frem

Keyset drevne markører
Denne markørfunktionalitet ligger mellem en statisk og en dynamisk markør om dets evne til at opdage ændringer. Det kan ikke altid registrere ændringer i resultatsættets medlemskab og rækkefølge som en statisk markør. Det kan registrere ændringer i resultatsættets rækkeværdier som en dynamisk markør. Det kan den kun flytte fra første til sidste og sidste til første række . Rækkefølgen og medlemskabet er fast, hver gang denne markør åbnes.
Den betjenes af et sæt unikke identifikatorer, der er de samme som nøglerne i nøglesættet. Nøglesættet bestemmes af alle rækker, der kvalificerede SELECT-sætningen, da markøren blev åbnet første gang. Den kan også registrere eventuelle ændringer i datakilden, som understøtter opdaterings- og sletningshandlinger. Den kan som standard rulles.
Implementering af eksempel
Lad os implementere markøreksemplet i SQL-serveren. Vi kan gøre dette ved først at oprette en tabel med navnet ' kunde ' ved hjælp af nedenstående erklæring:
hvordan man opgraderer java
CREATE TABLE customer ( id int PRIMARY KEY, c_name nvarchar(45) NOT NULL, email nvarchar(45) NOT NULL, city nvarchar(25) NOT NULL );
Dernæst vil vi indsætte værdier i tabellen. Vi kan udføre nedenstående sætning for at tilføje data til en tabel:
INSERT INTO customer (id, c_name, email, city) VALUES (1,'Steffen', '[email protected]', 'Texas'), (2, 'Joseph', '[email protected]', 'Alaska'), (3, 'Peter', '[email protected]', 'California'), (4,'Donald', '[email protected]', 'New York'), (5, 'Kevin', '[email protected]', 'Florida'), (6, 'Marielia', '[email protected]', 'Arizona'), (7,'Antonio', '[email protected]', 'New York'), (8, 'Diego', '[email protected]', 'California');
Vi kan verificere dataene ved at udføre VÆLG udmelding:
SELECT * FROM customer;
Efter at have udført forespørgslen, kan vi se nedenstående output, hvor vi har otte rækker ind i bordet:

Nu vil vi oprette en markør for at vise kunderegistreringerne. Nedenstående kodestykker forklarer alle trin i markørerklæringen eller oprettelsen ved at sætte alt sammen:
sorter array liste
--Declare the variables for holding data. DECLARE @id INT, @c_name NVARCHAR(50), @city NVARCHAR(50) --Declare and set counter. DECLARE @Counter INT SET @Counter = 1 --Declare a cursor DECLARE PrintCustomers CURSOR FOR SELECT id, c_name, city FROM customer --Open cursor OPEN PrintCustomers --Fetch the record into the variables. FETCH NEXT FROM PrintCustomers INTO @id, @c_name, @city --LOOP UNTIL RECORDS ARE AVAILABLE. WHILE @@FETCH_STATUS = 0 BEGIN IF @Counter = 1 BEGIN PRINT 'id' + CHAR(9) + 'c_name' + CHAR(9) + CHAR(9) + 'city' PRINT '--------------------------' END --Print the current record PRINT CAST(@id AS NVARCHAR(10)) + CHAR(9) + @c_name + CHAR(9) + CHAR(9) + @city --Increment the counter variable SET @Counter = @Counter + 1 --Fetch the next record into the variables. FETCH NEXT FROM PrintCustomers INTO @id, @c_name, @city END --Close the cursor CLOSE PrintCustomers --Deallocate the cursor DEALLOCATE PrintCustomers
Efter at have udført en markør, får vi nedenstående output:

Begrænsninger af SQL Server Cursor
En markør har nogle begrænsninger, så den altid kun skal bruges, når der ikke er nogen anden mulighed end markøren. Disse begrænsninger er:
- Markøren bruger netværksressourcer ved at kræve en netværksrundtur hver gang den henter en post.
- En markør er et hukommelsesresident sæt af pointere, hvilket betyder, at det kræver noget hukommelse, som andre processer kunne bruge på vores maskine.
- Det pålægger låse på en del af tabellen eller hele tabellen, når data behandles.
- Markørens ydeevne og hastighed er langsommere, fordi de opdaterer tabelposter én række ad gangen.
- Markører er hurtigere end while-løkker, men de har mere overhead.
- Antallet af rækker og kolonner, der bringes ind i markøren, er et andet aspekt, der påvirker markørens hastighed. Det refererer til, hvor lang tid det tager at åbne din markør og udføre en fetch-sætning.
Hvordan kan vi undgå markører?
Markørernes hovedopgave er at krydse tabellen række for række. Den nemmeste måde at undgå markører på er angivet nedenfor:
Brug af SQL while-løkken
Den nemmeste måde at undgå brugen af en markør på er ved at bruge en while-løkke, der tillader indsættelse af et resultatsæt i den midlertidige tabel.
Brugerdefinerede funktioner
Nogle gange bruges markører til at beregne det resulterende rækkesæt. Det kan vi opnå ved at bruge en brugerdefineret funktion, der opfylder kravene.
Brug af Joins
Join behandler kun de kolonner, der opfylder den specificerede betingelse, og reducerer dermed de kodelinjer, der giver hurtigere ydeevne end markører, hvis store poster skal behandles.