I operativsystemet skulle vi give input til CPU'en, og CPU'en udfører instruktionerne og giver til sidst output. Men der var et problem med denne tilgang. I en normal situation skal vi forholde os til mange processer, og vi ved, at den tid, det tager i I/O-operationen, er meget stor i forhold til den tid, CPU'en tager til at udføre instruktionerne. Så i den gamle tilgang vil en proces give input ved hjælp af en input-enhed, og i løbet af denne tid er CPU'en i en inaktiv tilstand.
ups i java
Så udfører CPU'en instruktionen, og outputtet gives igen til en eller anden outputenhed, og på dette tidspunkt er CPU'en også i en inaktiv tilstand. Efter at have vist outputtet, starter den næste proces sin udførelse. Så det meste af tiden er CPU'en inaktiv, hvilket er den værste tilstand, vi kan have i operativsystemer. Her kommer begrebet Spooling ind i billedet.
Hvad er spooling
Spooling er en proces, hvor data midlertidigt holdes til at blive brugt og eksekveret af en enhed, et program eller et system. Data sendes til og gemmes i hukommelsen eller andet flygtigt lager, indtil programmet eller computeren anmoder om det til eksekvering.
SPOOL er et akronym for samtidige perifere operationer online . Generelt bevares spoolen på computerens fysiske hukommelse, buffere eller de I/O-enhedsspecifikke interrupts. Spolen behandles i stigende rækkefølge og arbejder baseret på en FIFO (først-ind, først-ud) algoritme.
Spooling refererer til at lægge data fra forskellige I/O-job i en buffer. Denne buffer er et særligt område i hukommelsen eller harddisken, som er tilgængeligt for I/O-enheder. Et operativsystem udfører følgende aktiviteter relateret til det distribuerede miljø:
- Håndterer I/O-enhedsdataspooling, da enheder har forskellige dataadgangshastigheder.
- Vedligeholder spooling-bufferen, som giver en ventestation, hvor data kan hvile, mens den langsommere enhed indhenter.
- Vedligeholder parallel beregning på grund af spooling-processen, da en computer kan udføre I/O i parallel rækkefølge. Det bliver muligt at få computeren til at læse data fra et bånd, skrive data til disk og skrive ud til en båndprinter, mens den udfører sin computeropgave.
Hvordan spooling fungerer i operativsystemet
I et operativsystem fungerer spooling i følgende trin, såsom:
- Spooling involverer oprettelse af en buffer kaldet SPOOL, som bruges til at tilbageholde job og data, indtil den enhed, hvori SPOOL er oprettet, er klar til at bruge og udføre jobbet eller operere på dataene.
- Når en hurtigere enhed sender data til en langsommere enhed for at udføre en eller anden handling, bruger den enhver sekundær hukommelse, der er tilsluttet som en SPOOL-buffer. Disse data opbevares i SPOOL, indtil den langsommere enhed er klar til at betjene disse data. Når den langsommere enhed er klar, indlæses dataene i SPOOL i hovedhukommelsen til de nødvendige handlinger.
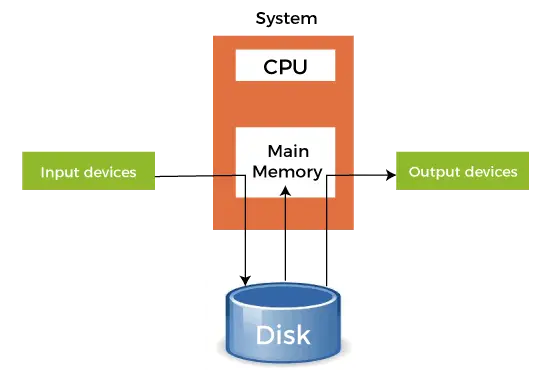
- Spooling betragter hele den sekundære hukommelse som en enorm buffer, der kan lagre mange job og data til mange operationer. Fordelen ved spooling er, at det kan skabe en kø af job, der udføres i FIFO-rækkefølge for at udføre jobs én efter én.
- En enhed kan oprette forbindelse til mange inputenheder, hvilket kan kræve en vis handling på deres data. Så alle disse input-enheder kan lægge deres data ind i den sekundære hukommelse (SPOOL), som derefter kan udføres en efter en af enheden. Dette vil sikre, at CPU'en ikke er inaktiv på noget tidspunkt. Så vi kan sige, at spooling er en kombination af buffering og kø.
- Efter at CPU'en har genereret noget output, gemmes dette output først i hovedhukommelsen. Dette output overføres til den sekundære hukommelse fra hovedhukommelsen, og derfra sendes output til de respektive outputenheder.

Eksempel på spooling
Det største eksempel på spooling er trykning . De dokumenter, der skal udskrives, gemmes i SPOOL og tilføjes derefter til udskrivningskøen. I løbet af denne tid kan mange processer udføre deres operationer og bruge CPU'en uden at vente, mens printeren udfører udskrivningsprocessen på dokumenterne én efter én.
b plus træ

Mange funktioner kan også føjes til Spooling-udskrivningsprocessen, som f.eks. at indstille prioriteter eller give besked, når udskrivningsprocessen er afsluttet, eller at vælge de forskellige typer papir, der skal udskrives på i henhold til brugerens valg.
Fordele ved spooling
Her er følgende fordele ved spooling i et operativsystem, såsom:
- Antallet af I/O-enheder eller operationer er ligegyldigt. Mange I/O-enheder kan arbejde sammen samtidigt uden interferens eller forstyrrelse af hinanden.
- Ved spooling er der ingen interaktion mellem I/O-enhederne og CPU'en. Det betyder, at der ikke er behov for, at CPU'en skal vente på, at I/O-handlingerne finder sted. Sådanne operationer tager lang tid at afslutte udførelsen, så CPU'en vil ikke vente på, at de er færdige.
- CPU i inaktiv tilstand anses ikke for særlig effektiv. De fleste protokoller er skabt til at udnytte CPU'en effektivt på et minimum af tid. Ved spooling holdes CPU'en beskæftiget det meste af tiden og går kun i inaktiv tilstand, når køen er opbrugt. Så alle opgaver føjes til køen, og CPU'en vil afslutte alle disse opgaver og derefter gå i inaktiv tilstand.
- Det giver applikationer mulighed for at køre med CPU'ens hastighed, mens I/O-enhederne betjenes ved deres respektive fulde hastigheder.
Ulemper ved spooling
I et operativsystem har spooling følgende ulemper, såsom:
- Spooling kræver en stor mængde lagerplads afhængigt af antallet af anmodninger fra inputtet og antallet af tilsluttede inputenheder.
- Fordi SPOOL er oprettet i det sekundære lager, kan mange input-enheder, der arbejder samtidigt, optage meget plads på det sekundære lager og dermed øge disktrafikken. Dette resulterer i, at disken bliver langsommere og langsommere, efterhånden som trafikken stiger mere og mere.
- Spooling bruges til at kopiere og udføre data fra en langsommere enhed til en hurtigere enhed. Den langsommere enhed opretter en SPOOL til at gemme de data, der skal betjenes i en kø, og CPU'en arbejder på den. Denne proces i sig selv gør spooling nytteløst at bruge i realtidsmiljøer, hvor vi har brug for realtidsresultater fra CPU'en. Dette skyldes, at inputenheden er langsommere og dermed producerer sine data i et langsommere tempo, mens CPU'en kan arbejde hurtigere, så den går videre til næste proces i køen. Dette er grunden til, at det endelige resultat eller output produceres på et senere tidspunkt i stedet for i realtid.
Forskellen mellem spooling og buffering
Spooling og buffering er de to måder, hvorpå I/O-undersystemer forbedrer computerens ydeevne og effektivitet ved at bruge en lagerplads i hovedhukommelsen eller på disken.

Den grundlæggende forskel mellem spooling og buffering er, at spooling overlapper I/O for et job med udførelsen af et andet job. Til sammenligning overlapper bufferingen I/O for et job med udførelsen af det samme job. Nedenfor er nogle flere forskelle mellem spooling og buffering, såsom:
| Betingelser | Spooling | Buffer |
|---|---|---|
| Definition | Spooling, et akronym af Simultaneous Peripheral Operation Online (SPOOL), placerer data i et midlertidigt arbejdsområde, som skal tilgås og behandles af et andet program eller ressource. | Buffer er en handling, hvor data gemmes midlertidigt i bufferen. Det hjælper med at matche hastigheden af datastrømmen mellem afsender og modtager. |
| Ressourcebehov | Spooling kræver mindre ressourcestyring, da forskellige ressourcer styrer processen for specifikke job. | Bufring kræver mere ressourcestyring, da den samme ressource styrer processen med det samme opdelte job. |
| Intern implementering | Spooling overlapper input og output fra et job med beregningen af et andet job. | Buffring overlapper input og output fra et job med beregningen af det samme job. |
| Effektiv | Spooling er mere effektivt end buffering. | Buffring er mindre effektivt end spooling. |
| Processor | Spooling kan også behandle data på fjerntliggende steder. Spooleren skal kun give besked, når en proces bliver fuldført på det eksterne sted for at spoole den næste proces til den eksterne enhed. | Buffer understøtter ikke fjernbehandling. |
| Størrelse på hukommelse | Det betragter disken som en enorm spole eller buffer. | Buffer er et begrænset område i hovedhukommelsen. |