Python er et fantastisk sprog til at lave dataanalyse, primært på grund af det fantastiske økosystem af datacentreret Python pakker. Pandaer er en af disse pakker og gør import og analyse af data meget nemmere.
Pandas DataFrame betyder()
Pandaer dataframe.mean() funktion returnerer middelværdien af værdierne for den anmodede akse. Hvis metoden anvendes på et pandaserieobjekt, returnerer metoden en skalarværdi, som er middelværdien af alle observationerne i Pandas dataramme . Hvis metoden anvendes på et Pandas Dataframe-objekt, returnerer metoden en Panda-serien objekt, som indeholder middelværdien af værdierne over den angivne akse.
Syntaks: DataFrame.mean(axis=0, skipna=True, level=None, numeric_only=False, **kwargs)
Parametre:
- akse : {indeks (0), kolonner (1)}
- ordre: Udelad NA/null-værdier ved beregning af resultatet
- niveau: Hvis aksen er et MultiIndex (hierarkisk), skal du tælle langs et bestemt niveau og kollapse til en serie
- kun numerisk: Inkluder kun float, int, booleske kolonner. Hvis Ingen, vil forsøge at bruge alt, så brug kun numeriske data. Ikke implementeret for serier.
Vender tilbage : betyder: Serier eller DataFrame (hvis niveau angivet)
latex matrix
Pandas DataFrame.mean() Eksempler
Eksempel 1:
Brug funktionen mean() til at finde middelværdien af alle observationerne over indeksaksen.
Python # importing pandas as pd import pandas as pd # Creating the dataframe df = pd.DataFrame({'A':[12, 4, 5, 44, 1], 'B':[5, 2, 54, 3, 2], 'C':[20, 16, 7, 3, 8], 'D':[14, 3, 17, 2, 6]}) # Print the dataframe df> 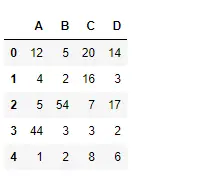
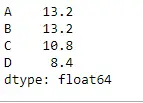
Lad os bruge funktionen Dataframe.mean() til at finde middelværdien over indeksaksen.
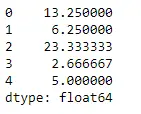
Python # Even if we do not specify axis = 0, # the method will return the mean over # the index axis by default df.mean(axis = 0)>
Produktion:
Eksempel 2:
Brug mean()-funktionen på en dataramme, der har ingen værdier. Find også middelværdien over søjleaksen.
Python # importing pandas as pd import pandas as pd # Creating the dataframe df = pd.DataFrame({'A':[12, 4, 5, None, 1], 'B':[7, 2, 54, 3, None], 'C':[20, 16, 11, 3, 8], 'D':[14, 3, None, 2, 6]}) # skip the Na values while finding the mean df.mean(axis = 1, skipna = True)> Produktion: