Pandaer dataframe.corr() bruges til at finde den parvise korrelation af alle kolonner i Pandas Dataframe i Python. Nogen NaN værdier udelukkes automatisk. For at ignorere ikke-numeriske værdier, brug parameteren numeric_only = True. I denne artikel vil vi lære om DataFrame.corr()-metoden i Python .
Pandas DataFrame corr() Metodesyntaks
Syntaks: DataFrame.corr(self, method='pearson', min_periods=1, numeric_only = False)
Parametre:
- metode:
- pearson: standard korrelationskoefficient
- kendall: Kendall Tau korrelationskoefficient
- spearman: Spearman rang korrelation
- min_perioder: Minimum antal observationer påkrævet pr. søjlepar for at få et gyldigt resultat. I øjeblikket kun tilgængelig for pearson og spearman korrelation
- numeric_only : Om kun de numeriske værdier skal betjenes eller ej. Den er som standard indstillet til False.
Vender tilbage: count :y : DataFrame
array.fra java
Pandas Data Correlations corr() Metode
En god korrelation afhænger af brugen, men det er sikkert at sige, at du har mindst 0,6 (eller -0,6) for at kalde det en god korrelation. Et simpelt eksempel til at vise, hvordan korrelation fungerer i Python .
Python3
import> pandas as pd> df>=> {> >'Array_1'>: [>30>,>70>,>100>],> >'Array_2'>: [>65.1>,>49.50>,>30.7>]> }> data>=> pd.DataFrame(df)> print>(data.corr())> |
>
>
Produktion
Array_1 Array_2 Array_1 1.000000 -0.990773 Array_2 -0.990773 1.000000>
Oprettelse af prøvedataramme
Udskrivning af de første 10 rækker af datarammen.
Bemærk: Korrelationen af en variabel med sig selv er 1. For et link til CSV-filen Brugt i Kode, klik her
Python3
polymorfi java
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df>=> pd.read_csv(>'nba.csv'>)> # Printing the first 10 rows of the data frame for visualization> df[:>10>]> |
>
>
Produktion

Python Pandas DataFrame corr() Metodeeksempler
Find sammenhæng mellem kolonnerne ved hjælp af pearson-metoden
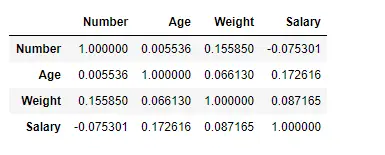
Her bruger vi corr()-funktionen til at finde korrelationen mellem kolonnerne i datarammen ved hjælp af 'Pearson'-metoden. Vi har kun fire numeriske kolonner i datarammen. Outputdatarammen kan fortolkes som for enhver celle, rækkevariabelkorrelation med kolonnevariablen er værdien af cellen. Som tidligere nævnt er korrelationen af en variabel med sig selv 1. Af den grund er alle diagonale værdier 1,00.
Python3
preg_match
# To find the correlation among> # the columns using pearson method> df.corr(method>=>'pearson'>)> |
>
>
Produktion
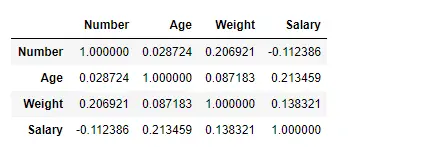
Find sammenhæng mellem kolonnerne ved hjælp af Kendall-metoden
Brug Pandas df.corr()-funktion til at finde korrelationen mellem kolonnerne i datarammen ved hjælp af 'kendall'-metoden. Outputdatarammen kan fortolkes som for enhver celle, rækkevariabelkorrelation med kolonnevariablen er værdien af cellen. Som tidligere nævnt er korrelationen af en variabel med sig selv 1. Af den grund er alle diagonale værdier 1,00.
Python3
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df>=> pd.read_csv(>'nba.csv'>)> # To find the correlation among> # the columns using kendall method> df.corr(method>=>'kendall'>)> |
int til streng c++
>
>
Produktion