EN hash tabel er en datastruktur, der giver mulighed for hurtig indsættelse, sletning og genfinding af data. Det fungerer ved at bruge en hash-funktion til at kortlægge en nøgle til et indeks i et array. I denne artikel vil vi implementere en hash-tabel i Python ved hjælp af separat kæde til at håndtere kollisioner.
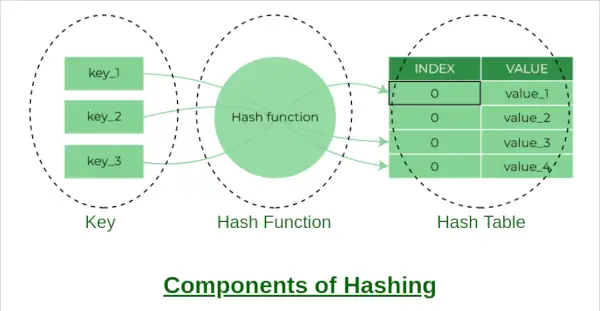
Komponenter af hashing
Separat kæde er en teknik, der bruges til at håndtere kollisioner i en hash-tabel. Når to eller flere nøgler er knyttet til det samme indeks i arrayet, gemmer vi dem i en sammenkædet liste ved det indeks. Dette giver os mulighed for at gemme flere værdier i samme indeks og stadig være i stand til at hente dem ved hjælp af deres nøgle.
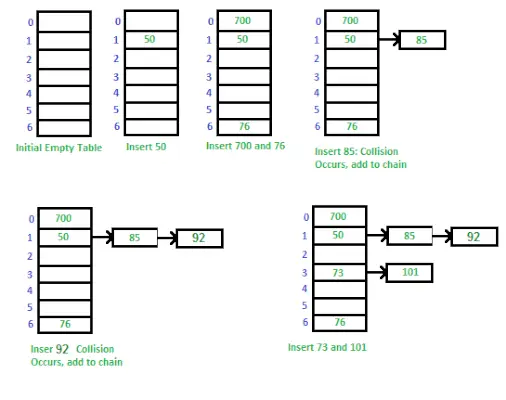
Måde at implementere Hash Table ved hjælp af Separate Chaining
Måde at implementere Hash-tabel ved hjælp af Separate Chaining:
Opret to klasser: ' Node 'og' HashTabel '.
Det ' Node ' klasse vil repræsentere en node i en sammenkædet liste. Hver knude vil indeholde et nøgleværdi-par samt en pegepind til den næste knude på listen.
Python3
class> Node:> >def> __init__(>self>, key, value):> >self>.key>=> key> >self>.value>=> value> >self>.>next> => None> |
>
>
'HashTable'-klassen vil indeholde det array, der skal indeholde de sammenkædede lister, samt metoder til at indsætte, hente og slette data fra hash-tabellen.
Python3
class> HashTable:> >def> __init__(>self>, capacity):> >self>.capacity>=> capacity> >self>.size>=> 0> >self>.table>=> [>None>]>*> capacity> |
>
>
Det ' __hed__ ' metode initialiserer hash-tabellen med en given kapacitet. Det sætter ' kapacitet 'og' størrelse ' variabler og initialiserer arrayet til 'Ingen'.
Den næste metode er ' _hash ’ metode. Denne metode tager en nøgle og returnerer et indeks i det array, hvor nøgle-værdi-parret skal gemmes. Vi vil bruge Pythons indbyggede hash-funktion til at hash nøglen og derefter bruge modulo-operatoren til at få et indeks i arrayet.
Python3
def> _hash(>self>, key):> >return> hash>(key)>%> self>.capacity> |
>
>
Det 'indsæt' metode vil indsætte et nøgle-værdi-par i hash-tabellen. Det tager indekset, hvor parret skal gemmes ved hjælp af ' _hash ’ metode. Hvis der ikke er nogen sammenkædet liste ved det indeks, opretter den en ny node med nøgleværdi-parret og indstiller den som listens hoved. Hvis der er en sammenkædet liste ved det indeks, skal du gentage listen, indtil den sidste node er fundet, eller nøglen allerede eksisterer, og opdatere værdien, hvis nøglen allerede eksisterer. Hvis den finder nøglen, opdaterer den værdien. Hvis den ikke finder nøglen, opretter den en ny node og tilføjer den til listens hoved.
Python3
def> insert(>self>, key, value):> >index>=> self>._hash(key)> >if> self>.table[index]>is> None>:> >self>.table[index]>=> Node(key, value)> >self>.size>+>=> 1> >else>:> >current>=> self>.table[index]> >while> current:> >if> current.key>=>=> key:> >current.value>=> value> >return> >current>=> current.>next> >new_node>=> Node(key, value)> >new_node.>next> => self>.table[index]> >self>.table[index]>=> new_node> >self>.size>+>=> 1> |
>
>
Det Søg metoden henter den værdi, der er knyttet til en given nøgle. Den får først indekset, hvor nøgleværdi-parret skal gemmes ved hjælp af _hash metode. Den søger derefter på den linkede liste i det indeks efter nøglen. Hvis den finder nøglen, returnerer den den tilknyttede værdi. Hvis den ikke finder nøglen, rejser den en KeyError .
Python3
def> search(>self>, key):> >index>=> self>._hash(key)> >current>=> self>.table[index]> >while> current:> >if> current.key>=>=> key:> >return> current.value> >current>=> current.>next> >raise> KeyError(key)> |
>
>
Det 'fjerne' metode fjerner et nøgle-værdi-par fra hash-tabellen. Den får først indekset, hvor parret skal gemmes ved hjælp af ` _hash ` metode. Den søger derefter på den linkede liste i det indeks efter nøglen. Hvis den finder nøglen, fjerner den noden fra listen. Hvis den ikke finder nøglen, rejser den en ` KeyError `.
Python3
def> remove(>self>, key):> >index>=> self>._hash(key)> > >previous>=> None> >current>=> self>.table[index]> > >while> current:> >if> current.key>=>=> key:> >if> previous:> >previous.>next> => current.>next> >else>:> >self>.table[index]>=> current.>next> >self>.size>->=> 1> >return> >previous>=> current> >current>=> current.>next> > >raise> KeyError(key)> |
>
>
'__str__' metode, der returnerer en strengrepræsentation af hash-tabellen.
Python3
def> __str__(>self>):> >elements>=> []> >for> i>in> range>(>self>.capacity):> >current>=> self>.table[i]> >while> current:> >elements.append((current.key, current.value))> >current>=> current.>next> >return> str>(elements)> |
>
>
Her er den komplette implementering af 'HashTable'-klassen:
Python3
class> Node:> >def> __init__(>self>, key, value):> >self>.key>=> key> >self>.value>=> value> >self>.>next> => None> > > class> HashTable:> >def> __init__(>self>, capacity):> >self>.capacity>=> capacity> >self>.size>=> 0> >self>.table>=> [>None>]>*> capacity> > >def> _hash(>self>, key):> >return> hash>(key)>%> self>.capacity> > >def> insert(>self>, key, value):> >index>=> self>._hash(key)> > >if> self>.table[index]>is> None>:> >self>.table[index]>=> Node(key, value)> >self>.size>+>=> 1> >else>:> >current>=> self>.table[index]> >while> current:> >if> current.key>=>=> key:> >current.value>=> value> >return> >current>=> current.>next> >new_node>=> Node(key, value)> >new_node.>next> => self>.table[index]> >self>.table[index]>=> new_node> >self>.size>+>=> 1> > >def> search(>self>, key):> >index>=> self>._hash(key)> > >current>=> self>.table[index]> >while> current:> >if> current.key>=>=> key:> >return> current.value> >current>=> current.>next> > >raise> KeyError(key)> > >def> remove(>self>, key):> >index>=> self>._hash(key)> > >previous>=> None> >current>=> self>.table[index]> > >while> current:> >if> current.key>=>=> key:> >if> previous:> >previous.>next> => current.>next> >else>:> >self>.table[index]>=> current.>next> >self>.size>->=> 1> >return> >previous>=> current> >current>=> current.>next> > >raise> KeyError(key)> > >def> __len__(>self>):> >return> self>.size> > >def> __contains__(>self>, key):> >try>:> >self>.search(key)> >return> True> >except> KeyError:> >return> False> > > # Driver code> if> __name__>=>=> '__main__'>:> > ># Create a hash table with> ># a capacity of 5> >ht>=> HashTable(>5>)> > ># Add some key-value pairs> ># to the hash table> >ht.insert(>'apple'>,>3>)> >ht.insert(>'banana'>,>2>)> >ht.insert(>'cherry'>,>5>)> > ># Check if the hash table> ># contains a key> >print>(>'apple'> in> ht)># True> >print>(>'durian'> in> ht)># False> > ># Get the value for a key> >print>(ht.search(>'banana'>))># 2> > ># Update the value for a key> >ht.insert(>'banana'>,>4>)> >print>(ht.search(>'banana'>))># 4> > >ht.remove(>'apple'>)> ># Check the size of the hash table> >print>(>len>(ht))># 3> |
>
>
10 ml til ouncesProduktion
True False 2 4 3>
Tidskompleksitet og rumkompleksitet:
- Det tidskompleksitet af indsætte , Søg og fjerne metoder i en hash-tabel ved hjælp af separat kæde afhænger af størrelsen af hash-tabellen, antallet af nøgle-værdi-par i hash-tabellen og længden af den sammenkædede liste ved hvert indeks.
- Forudsat en god hash-funktion og en ensartet fordeling af nøgler, er den forventede tidskompleksitet af disse metoder O(1) for hver operation. Men i værste fald kan tidskompleksiteten være På) , hvor n er antallet af nøgleværdi-par i hashtabellen.
- Det er dog vigtigt at vælge en god hashfunktion og en passende størrelse til hashtabellen for at minimere sandsynligheden for kollisioner og sikre en god ydeevne.
- Det rummets kompleksitet af en hash-tabel, der bruger separat kæde, afhænger af størrelsen af hash-tabellen og antallet af nøgle-værdi-par, der er gemt i hash-tabellen.
- Selve hashtabellen tager O(m) rum, hvor m er hashtabellens kapacitet. Hver linket listeknude tager O(1) mellemrum, og der kan højst være n noder i de sammenkædede lister, hvor n er antallet af nøgleværdi-par gemt i hash-tabellen.
- Derfor er den samlede rumkompleksitet O(m + n) .
Konklusion:
I praksis er det vigtigt at vælge en passende kapacitet til hashtabellen for at balancere pladsforbruget og sandsynligheden for kollisioner. Hvis kapaciteten er for lille, øges sandsynligheden for kollisioner, hvilket kan forårsage forringelse af ydeevnen. På den anden side, hvis kapaciteten er for stor, kan hashtabellen forbruge mere hukommelse end nødvendigt.