Pandas-modulet indeholder forskellige funktioner til at udføre forskellige operationer på Dataframes som join, concatenate, delete, add osv. I denne artikel vil vi diskutere de forskellige typer join-operationer, der kan udføres på Pandas Dataramme. Der er fem typer Joins in Pandaer .
- Indre Join
- Venstre Ydre Sammenføjning
- Højre ydre samling
- Full Outer Join eller blot Outer Join
- Indeks Deltag
For at forstå forskellige typer joinforbindelser vil vi først lave to DataFrames, nemlig -en og b .
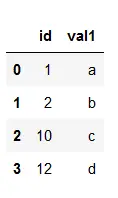
Dataramme a:
Python3
# importing pandas> import> pandas as pd> # Creating dataframe a> a>=> pd.DataFrame()> # Creating Dictionary> d>=> {>'id'>: [>1>,>2>,>10>,>12>],> >'val1'>: [>'a'>,>'b'>,>'c'>,>'d'>]}> a>=> pd.DataFrame(d)> # printing the dataframe> a> |
>
tostring metode java
>
Produktion:
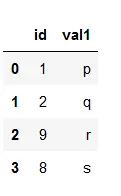
DataFrame b:
Python3
# importing pandas> import> pandas as pd> # Creating dataframe b> b>=> pd.DataFrame()> # Creating dictionary> d>=> {>'id'>: [>1>,>2>,>9>,>8>],> >'val1'>: [>'p'>,>'q'>,>'r'>,>'s'>]}> b>=> pd.DataFrame(d)> # printing the dataframe> b> |
>
>
Produktion:
Typer af sammenføjninger i pandaer
Vi vil bruge disse to Dataframes til at forstå de forskellige typer joinforbindelser.
Pandaer Indre Join
Inner join er den mest almindelige type join, du vil arbejde med. Det returnerer en dataramme med kun de rækker, der har fælles karakteristika. Dette svarer til skæringspunktet mellem to sæt.
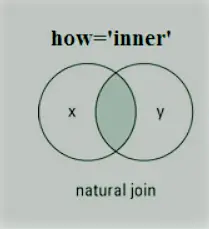
Eksempel:
Python3
# importing pandas> import> pandas as pd> # Creating dataframe a> a>=> pd.DataFrame()> # Creating Dictionary> d>=> {>'id'>: [>1>,>2>,>10>,>12>],> >'val1'>: [>'a'>,>'b'>,>'c'>,>'d'>]}> a>=> pd.DataFrame(d)> # Creating dataframe b> b>=> pd.DataFrame()> # Creating dictionary> d>=> {>'id'>: [>1>,>2>,>9>,>8>],> >'val1'>: [>'p'>,>'q'>,>'r'>,>'s'>]}> b>=> pd.DataFrame(d)> # inner join> df>=> pd.merge(a, b, on>=>'id'>, how>=>'inner'>)> # display dataframe> df> |
>
>
anmærkninger i springstøvle
Produktion:

Pandaer Venstre Deltag
Med en venstre ydre join vil alle posterne fra den første Dataframe blive vist, uanset om nøglerne i den første Dataframe kan findes i den anden Dataframe. Hvorimod, for den anden Dataframe, vil kun posterne med nøglerne i den anden Dataframe, som kan findes i den første Dataframe, blive vist.
 Eksempel:
Eksempel:
Python3
uordensgennemgang af binært træ
# importing pandas> import> pandas as pd> # Creating dataframe a> a>=> pd.DataFrame()> # Creating Dictionary> d>=> {>'id'>: [>1>,>2>,>10>,>12>],> >'val1'>: [>'a'>,>'b'>,>'c'>,>'d'>]}> a>=> pd.DataFrame(d)> # Creating dataframe b> b>=> pd.DataFrame()> # Creating dictionary> d>=> {>'id'>: [>1>,>2>,>9>,>8>],> >'val1'>: [>'p'>,>'q'>,>'r'>,>'s'>]}> b>=> pd.DataFrame(d)> # left outer join> df>=> pd.merge(a, b, on>=>'id'>, how>=>'left'>)> # display dataframe> df> |
>
>
Produktion:

Pandaer Højre ydre samling
For en højre join vil alle posterne fra den anden Dataframe blive vist. Det er dog kun de poster med nøglerne i den første Dataframe, der kan findes i den anden Dataframe, der vil blive vist.

Eksempel:
Python3
1 million tal
# importing pandas> import> pandas as pd> # Creating dataframe a> a>=> pd.DataFrame()> # Creating Dictionary> d>=> {>'id'>: [>1>,>2>,>10>,>12>],> >'val1'>: [>'a'>,>'b'>,>'c'>,>'d'>]}> a>=> pd.DataFrame(d)> # Creating dataframe b> b>=> pd.DataFrame()> # Creating dictionary> d>=> {>'id'>: [>1>,>2>,>9>,>8>],> >'val1'>: [>'p'>,>'q'>,>'r'>,>'s'>]}> b>=> pd.DataFrame(d)> # right outer join> df>=> pd.merge(a, b, on>=>'id'>, how>=>'right'>)> # display dataframe> df> |
>
>
Produktion:

Pandaer Fuld ydre sammenføjning
En fuld ydre joinforbindelse returnerer alle rækkerne fra venstre Dataframe og alle rækkerne fra højre Dataframe og matcher rækker, hvor det er muligt, med NaN'er andre steder. Men hvis Dataframe er komplet, så får vi det samme output.

Eksempel:
Python3
# importing pandas> import> pandas as pd> # Creating dataframe a> a>=> pd.DataFrame()> # Creating Dictionary> d>=> {>'id'>: [>1>,>2>,>10>,>12>],> >'val1'>: [>'a'>,>'b'>,>'c'>,>'d'>]}> a>=> pd.DataFrame(d)> # Creating dataframe b> b>=> pd.DataFrame()> # Creating dictionary> d>=> {>'id'>: [>1>,>2>,>9>,>8>],> >'val1'>: [>'p'>,>'q'>,>'r'>,>'s'>]}> b>=> pd.DataFrame(d)> # full outer join> df>=> pd.merge(a, b, on>=>'id'>, how>=>'outer'>)> # display dataframe> df> |
matematik tilfældig java
>
>
Produktion:

Pandas Index Deltag
For at flette datarammen på indekser bestå venstre_indeks og højre_indeks argumenter som sande, dvs. begge dataframes er flettet på et indeks ved at bruge standard indre sammenkædning.
Python3
# importing pandas> import> pandas as pd> # Creating dataframe a> a>=> pd.DataFrame()> # Creating Dictionary> d>=> {>'id'>: [>1>,>2>,>10>,>12>],> >'val1'>: [>'a'>,>'b'>,>'c'>,>'d'>]}> a>=> pd.DataFrame(d)> # Creating dataframe b> b>=> pd.DataFrame()> # Creating dictionary> d>=> {>'id'>: [>1>,>2>,>9>,>8>],> >'val1'>: [>'p'>,>'q'>,>'r'>,>'s'>]}> b>=> pd.DataFrame(d)> # index join> df>=> pd.merge(a, b, left_index>=>True>, right_index>=>True>)> # display dataframe> df> |
>
>
Produktion:
