I denne artikel vil vi diskutere DFS-algoritmen i datastrukturen. Det er en rekursiv algoritme til at søge i alle hjørnerne af en trædatastruktur eller en graf. Depth-first search (DFS)-algoritmen starter med den indledende node af graf G og går dybere, indtil vi finder målknuden eller noden uden børn.
På grund af den rekursive natur kan stakdatastrukturen bruges til at implementere DFS-algoritmen. Processen med at implementere DFS ligner BFS-algoritmen.
Den trinvise proces til implementering af DFS-gennemgangen er givet som følger -
cast int til streng java
- Først skal du oprette en stak med det samlede antal hjørner i grafen.
- Vælg nu et hvilket som helst toppunkt som startpunkt for gennemkøring, og skub det toppunkt ind i stakken.
- Skub derefter et ikke-besøgt toppunkt (ved siden af toppunktet på toppen af stakken) til toppen af stakken.
- Gentag nu trin 3 og 4, indtil der ikke er nogen hjørner tilbage at besøge fra toppunktet på stakkens top.
- Hvis der ikke er et toppunkt tilbage, skal du gå tilbage og springe et toppunkt fra stakken.
- Gentag trin 2, 3 og 4, indtil stakken er tom.
Anvendelser af DFS-algoritme
Anvendelserne for at bruge DFS-algoritmen er givet som følger -
- DFS-algoritme kan bruges til at implementere den topologiske sortering.
- Det kan bruges til at finde stierne mellem to hjørner.
- Det kan også bruges til at detektere cyklusser i grafen.
- DFS-algoritme bruges også til én løsnings gåder.
- DFS bruges til at bestemme, om en graf er todelt eller ej.
Algoritme
Trin 1: SET STATUS = 1 (klar tilstand) for hver node i G
Trin 2: Skub startknudepunktet A på stakken og indstil dens STATUS = 2 (ventetilstand)
Trin 3: Gentag trin 4 og 5, indtil STAKKEN er tom
Trin 4: Pop den øverste node N. Bearbejd den og indstil dens STATUS = 3 (behandlet tilstand)
Trin 5: Skub på stakken alle naboerne til N, der er i klar tilstand (hvis STATUS = 1) og indstil deres STATUS = 2 (ventetilstand)
[SLUKKE SLUT]
Trin 6: AFSLUT
til loop bash
Pseudokode
DFS(G,v) ( v is the vertex where the search starts ) Stack S := {}; ( start with an empty stack ) for each vertex u, set visited[u] := false; push S, v; while (S is not empty) do u := pop S; if (not visited[u]) then visited[u] := true; for each unvisited neighbour w of uu push S, w; end if end while END DFS() Eksempel på DFS-algoritme
Lad os nu forstå, hvordan DFS-algoritmen fungerer ved at bruge et eksempel. I eksemplet nedenfor er der en rettet graf med 7 hjørner.
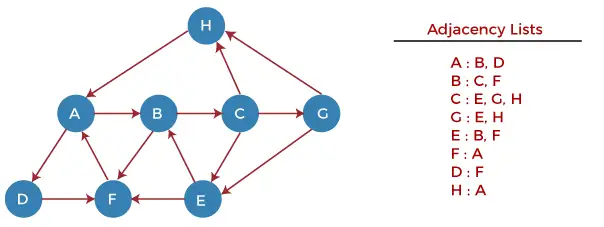
Lad os nu begynde at undersøge grafen fra Node H.
Trin 1 - Skub først H ind på stakken.
spil pigeon android
STACK: H
Trin 2 - POP det øverste element fra stakken, dvs. H, og udskriv det. SKUB nu alle naboerne til H ind på stakken, der er klar.
Print: H]STACK: A
Trin 3 - POP det øverste element fra stakken, dvs. A, og udskriv det. SKUB nu alle naboerne til A ind på stakken, der er klar.
Print: A STACK: B, D
Trin 4 - POP det øverste element fra stakken, dvs. D, og udskriv det. SKUB nu alle naboerne til D ind på stakken, der er klar.
Print: D STACK: B, F
Trin 5 - POP det øverste element fra stakken, dvs. F, og udskriv det. SKUB nu alle naboerne til F ind på stakken, der er klar.
Print: F STACK: B
Trin 6 - POP det øverste element fra stakken, dvs. B, og udskriv det. SKUB nu alle naboerne til B ind på stakken, der er klar.
Print: B STACK: C
Trin 7 - POP det øverste element fra stakken, dvs. C, og udskriv det. SKUB nu alle naboerne til C ind på stakken, der er klar.
Print: C STACK: E, G
Trin 8 - POP det øverste element fra stakken, dvs. G og SKUB alle naboerne til G ind på stakken, der er i klar tilstand.
Print: G STACK: E
Trin 9 - POP det øverste element fra stakken, dvs. E og SKUB alle naboerne til E på stakken, der er i klar tilstand.
Print: E STACK:
Nu er alle grafknuderne gennemløbet, og stakken er tom.
Kompleksiteten af dybde-først søgealgoritme
Tidskompleksiteten af DFS-algoritmen er O(V+E) , hvor V er antallet af hjørner og E er antallet af kanter i grafen.
streng i java-metoder
Rumkompleksiteten af DFS-algoritmen er O(V).
Implementering af DFS-algoritme
Lad os nu se implementeringen af DFS-algoritmen i Java.
I dette eksempel er grafen, som vi bruger til at demonstrere koden, givet som følger -

/*A sample java program to implement the DFS algorithm*/ import java.util.*; class DFSTraversal { private LinkedList adj[]; /*adjacency list representation*/ private boolean visited[]; /* Creation of the graph */ DFSTraversal(int V) /*'V' is the number of vertices in the graph*/ { adj = new LinkedList[V]; visited = new boolean[V]; for (int i = 0; i <v; i++) adj[i]="new" linkedlist(); } * adding an edge to the graph void insertedge(int src, int dest) { adj[src].add(dest); dfs(int vertex) visited[vertex]="true;" *mark current node as visited* system.out.print(vertex + ' '); iterator it="adj[vertex].listIterator();" while (it.hasnext()) n="it.next();" if (!visited[n]) dfs(n); public static main(string args[]) dfstraversal dfstraversal(8); graph.insertedge(0, 1); 2); 3); graph.insertedge(1, graph.insertedge(2, 4); graph.insertedge(3, 5); 6); graph.insertedge(4, 7); graph.insertedge(5, system.out.println('depth first traversal for is:'); graph.dfs(0); < pre> <p> <strong>Output</strong> </p> <img src="//techcodeview.com/img/ds-tutorial/28/dfs-algorithm-3.webp" alt="DFS algorithm"> <h3>Conclusion</h3> <p>In this article, we have discussed the depth-first search technique, its example, complexity, and implementation in the java programming language. Along with that, we have also seen the applications of the depth-first search algorithm.</p> <p>So, that's all about the article. Hope it will be helpful and informative to you.</p> <hr></v;>