Hvad er LRU Cache?
Algoritmer til udskiftning af cache er effektivt designet til at erstatte cachen, når pladsen er fuld. Det Sidst brugt (LRU) er en af disse algoritmer. Som navnet antyder, når cachehukommelsen er fuld, LRU vælger de data, der er brugt mindst for nylig, og fjerner dem for at gøre plads til de nye data. Prioriteten af dataene i cachen ændres i overensstemmelse med behovet for disse data, dvs. hvis nogle data hentes eller opdateres for nylig, så vil disse datas prioritet blive ændret og tildelt den højeste prioritet, og prioriteten af dataene falder, hvis den forbliver ubrugte operationer efter operationer.
Indholdsfortegnelse
- Hvad er LRU Cache?
- Operationer på LRU Cache:
- Arbejde med LRU Cache:
- Måder at implementere LRU-cache på:
- LRU-cache-implementering ved hjælp af kø og hashing:
- LRU-cache-implementering ved hjælp af dobbeltlinket liste og hashing:
- LRU-cache-implementering ved hjælp af Deque & Hashmap:
- LRU-cache-implementering ved hjælp af Stack & Hashmap:
- LRU-cache ved hjælp af tællerimplementering:
- LRU-cacheimplementering ved hjælp af Lazy Updates:
- Kompleksitetsanalyse af LRU-cache:
- Fordele ved LRU-cache:
- Ulemper ved LRU-cache:
- Real-World Anvendelse af LRU Cache:
LRU Algoritme er et standardproblem, og det kan have variationer efter behov, for eksempel i operativsystemer LRU spiller en afgørende rolle, da den kan bruges som en sideerstatningsalgoritme for at minimere sidefejl.
Operationer på LRU Cache:
- LRUCache (Kapacitet c): Initialiser LRU-cache med positiv størrelseskapacitet c.
- få (nøgle) : Returnerer værdien af Key ' k' hvis det er til stede i cachen ellers returnerer det -1. Opdaterer også prioriteten af data i LRU-cachen.
- put (nøgle, værdi): Opdater værdien af nøglen, hvis denne nøgle findes. Ellers skal du tilføje nøgleværdi-par til cachen. Hvis antallet af nøgler overskred LRU-cachens kapacitet, skal du afvise den senest brugte nøgle.
Arbejde med LRU Cache:
Lad os antage, at vi har en LRU-cache med kapacitet 3, og vi vil gerne udføre følgende operationer:
- Sæt (nøgle=1, værdi=A) i cachen
- Sæt (nøgle=2, værdi=B) i cachen
- Sæt (nøgle=3, værdi=C) i cachen
- Hent (nøgle=2) fra cachen
- Hent (nøgle=4) fra cachen
- Sæt (nøgle=4, værdi=D) i cachen
- Sæt (nøgle=3, værdi=E) i cachen
- Hent (nøgle=4) fra cachen
- Sæt (nøgle=1, værdi=A) i cachen
Ovenstående operationer udføres en efter en som vist på billedet nedenfor:
Detaljeret forklaring af hver operation:
- Sæt (nøgle 1, værdi A) : Da LRU-cache har tom kapacitet=3, er der ikke behov for nogen erstatning, og vi sætter {1 : A} øverst, dvs. {1 : A} har højeste prioritet.
- Sæt (nøgle 2, værdi B) : Da LRU-cachen har tom kapacitet=2, er der igen ikke behov for nogen udskiftning, men nu har {2 : B} den højeste prioritet og prioritet på {1 : A} reduktion.
- Sæt (nøgle 3, værdi C) : Der er stadig 1 tom plads ledig i cachen, så indsæt {3 : C} uden nogen erstatning, bemærk nu, at cachen er fuld, og den aktuelle prioritetsrækkefølge fra højeste til laveste er {3:C}, {2:B }, {1:A}.
- Hent (tast 2) : Returner nu værdien af key=2 under denne operation, også da key=2 bruges, er den nye prioritetsrækkefølge nu {2:B}, {3:C}, {1:A}
- Hent (nøgle 4): Bemærk, at nøgle 4 ikke er til stede i cachen, vi returnerer '-1' for denne operation.
- Sæt (nøgle 4, værdi D) : Bemærk, at cachen er FULD, brug nu LRU-algoritmen til at bestemme, hvilken nøgle der er mindst brugt for nylig. Da {1:A} havde den mindste prioritet, skal du fjerne {1:A} fra vores cache og sætte {4:D} ind i cachen. Bemærk, at den nye prioritetsrækkefølge er {4:D}, {2:B}, {3:C}
- Sæt (nøgle 3, værdi E) : Da key=3 allerede var til stede i cachen med værdien=C, vil denne operation ikke resultere i fjernelse af nogen nøgle, snarere vil den opdatere værdien af key=3 til ' OG' . Nu bliver den nye prioritetsrækkefølge {3:E}, {4:D}, {2:B}
- Hent (tast 4) : Returner værdien af nøgle=4. Nu bliver ny prioritet {4:D}, {3:E}, {2:B}
- Sæt (nøgle 1, værdi A) : Da vores cache er FULD, så brug vores LRU-algoritme til at bestemme, hvilken nøgle der blev brugt mindst for nylig, og da {2:B} havde den mindste prioritet, skal du fjerne {2:B} fra vores cache og sætte {1:A} i cache. Nu er den nye prioritetsrækkefølge {1:A}, {4:D}, {3:E}
Måder at implementere LRU-cache på:
LRU-cache kan implementeres på en række forskellige måder, og hver programmør kan vælge en anden tilgang. Nedenstående er dog almindeligt anvendte tilgange:
- LRU ved hjælp af kø og hashing
- LRU bruger Dobbelt linket liste + hashing
- LRU ved hjælp af Deque
- LRU ved hjælp af Stack
- LRU bruger Modimplementering
- LRU ved hjælp af Lazy Updates
LRU-cache-implementering ved hjælp af kø og hashing:
Vi bruger to datastrukturer til at implementere en LRU Cache.
- Kø implementeres ved hjælp af en dobbelt-linket liste. Den maksimale størrelse af køen vil være lig med det samlede antal tilgængelige rammer (cachestørrelse). De senest brugte sider vil være tæt på forsiden, og de senest brugte sider vil være tæt på bagenden.
- En Hash med sidenummeret som nøgle og adressen på den tilsvarende køknude som værdi.
Når der henvises til en side, kan den påkrævede side være i hukommelsen. Hvis det er i hukommelsen, skal vi fjerne listens node og bringe den foran i køen.
Hvis den påkrævede side ikke er i hukommelsen, bringer vi den i hukommelsen. Med enkle ord tilføjer vi en ny node foran i køen og opdaterer den tilsvarende nodeadresse i hashen. Hvis køen er fuld, dvs. alle rammer er fulde, fjerner vi en node fra den bagerste del af køen og tilføjer den nye node foran i køen.
Illustration:
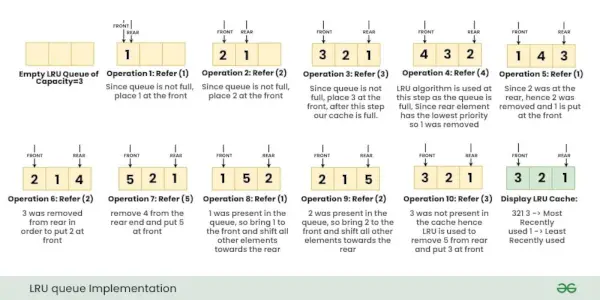
Lad os overveje operationerne, Henviser nøgle x med i LRU-cachen: { 1, 2, 3, 4, 1, 2, 5, 1, 2, 3 }
Bemærk: Til at begynde med er der ingen side i hukommelsen.Nedenstående billeder viser trin for trin udførelse af ovenstående operationer på LRU-cachen.
Algoritme:
- Opret en klasse LRUCache med erklære en liste af typen int, et uordnet kort af typen
- I referencefunktionen af LRUCache
- Hvis denne værdi ikke er til stede i køen, så skub denne værdi foran køen og fjern den sidste værdi, hvis køen er fuld
- Hvis værdien allerede er til stede, så fjern den fra køen og skub den foran i køen
- I displayfunktionen print, LRUCache ved hjælp af køen starter forfra
Nedenfor er implementeringen af ovenstående tilgang:
C++
// We can use stl container list as a double> // ended queue to store the cache keys, with> // the descending time of reference from front> // to back and a set container to check presence> // of a key. But to fetch the address of the key> // in the list using find(), it takes O(N) time.> // This can be optimized by storing a reference> // (iterator) to each key in a hash map.> #include> using> namespace> std;> > class> LRUCache {> >// store keys of cache> >list<>int>>dq;> > >// store references of key in cache> >unordered_map<>int>, list<>int>>::iterator> ma;> >int> csize;>// maximum capacity of cache> > public>:> >LRUCache(>int>);> >void> refer(>int>);> >void> display();> };> > // Declare the size> LRUCache::LRUCache(>int> n) { csize = n; }> > // Refers key x with in the LRU cache> void> LRUCache::refer(>int> x)> {> >// not present in cache> >if> (ma.find(x) == ma.end()) {> >// cache is full> >if> (dq.size() == csize) {> >// delete least recently used element> >int> last = dq.back();> > >// Pops the last element> >dq.pop_back();> > >// Erase the last> >ma.erase(last);> >}> >}> > >// present in cache> >else> >dq.erase(ma[x]);> > >// update reference> >dq.push_front(x);> >ma[x] = dq.begin();> }> > // Function to display contents of cache> void> LRUCache::display()> {> > >// Iterate in the deque and print> >// all the elements in it> >for> (>auto> it = dq.begin(); it != dq.end(); it++)> >cout << (*it) <<>' '>;> > >cout << endl;> }> > // Driver Code> int> main()> {> >LRUCache ca(4);> > >ca.refer(1);> >ca.refer(2);> >ca.refer(3);> >ca.refer(1);> >ca.refer(4);> >ca.refer(5);> >ca.display();> > >return> 0;> }> // This code is contributed by Satish Srinivas> |
>
>
C
java navngivningskonventioner
// A C program to show implementation of LRU cache> #include> #include> > // A Queue Node (Queue is implemented using Doubly Linked> // List)> typedef> struct> QNode {> >struct> QNode *prev, *next;> >unsigned> >pageNumber;>// the page number stored in this QNode> } QNode;> > // A Queue (A FIFO collection of Queue Nodes)> typedef> struct> Queue {> >unsigned count;>// Number of filled frames> >unsigned numberOfFrames;>// total number of frames> >QNode *front, *rear;> } Queue;> > // A hash (Collection of pointers to Queue Nodes)> typedef> struct> Hash {> >int> capacity;>// how many pages can be there> >QNode** array;>// an array of queue nodes> } Hash;> > // A utility function to create a new Queue Node. The queue> // Node will store the given 'pageNumber'> QNode* newQNode(unsigned pageNumber)> {> >// Allocate memory and assign 'pageNumber'> >QNode* temp = (QNode*)>malloc>(>sizeof>(QNode));> >temp->pageNumber = pageNumber;> > >// Initialize prev and next as NULL> >temp->prev = temp->next = NULL;> > >return> temp;> }> > // A utility function to create an empty Queue.> // The queue can have at most 'numberOfFrames' nodes> Queue* createQueue(>int> numberOfFrames)> {> >Queue* queue = (Queue*)>malloc>(>sizeof>(Queue));> > >// The queue is empty> >queue->tælle = 0;> >queue->front = kø->bagside = NULL;> > >// Number of frames that can be stored in memory> >queue->numberOfFrames = numberOfFrames;> > >return> queue;> }> > // A utility function to create an empty Hash of given> // capacity> Hash* createHash(>int> capacity)> {> >// Allocate memory for hash> >Hash* hash = (Hash*)>malloc>(>sizeof>(Hash));> >hash->kapacitet = kapacitet;> > >// Create an array of pointers for referring queue nodes> >hash->array> >= (QNode**)>malloc>(hash->kapacitet *>sizeof>(QNode*));> > >// Initialize all hash entries as empty> >int> i;> >for> (i = 0; i capacity; ++i)> >hash->array[i] = NULL;> > >return> hash;> }> > // A function to check if there is slot available in memory> int> AreAllFramesFull(Queue* queue)> {> >return> queue->antal == kø->antalFrames;> }> > // A utility function to check if queue is empty> int> isQueueEmpty(Queue* queue)> {> >return> queue->bagside == NULL;> }> > // A utility function to delete a frame from queue> void> deQueue(Queue* queue)> {> >if> (isQueueEmpty(queue))> >return>;> > >// If this is the only node in list, then change front> >if> (queue->foran == kø->bag)> >queue->front = NULL;> > >// Change rear and remove the previous rear> >QNode* temp = queue->bag;> >queue->rear = kø->bag->prev;> > >if> (queue->bag)> >queue->bag->næste = NULL;> > >free>(temp);> > >// decrement the number of full frames by 1> >queue->tælle--;> }> > // A function to add a page with given 'pageNumber' to both> // queue and hash> void> Enqueue(Queue* queue, Hash* hash, unsigned pageNumber)> {> >// If all frames are full, remove the page at the rear> >if> (AreAllFramesFull(queue)) {> >// remove page from hash> >hash->array[queue->rear->pageNumber] = NULL;> >deQueue(queue);> >}> > >// Create a new node with given page number,> >// And add the new node to the front of queue> >QNode* temp = newQNode(pageNumber);> >temp->næste = kø->front;> > >// If queue is empty, change both front and rear> >// pointers> >if> (isQueueEmpty(queue))> >queue->bagside = kø->front = temp;> >else> // Else change the front> >{> >queue->front->prev = temp;> >queue->front = temp;> >}> > >// Add page entry to hash also> >hash->array[pageNumber] = temp;> > >// increment number of full frames> >queue->tælle++;> }> > // This function is called when a page with given> // 'pageNumber' is referenced from cache (or memory). There> // are two cases:> // 1. Frame is not there in memory, we bring it in memory> // and add to the front of queue> // 2. Frame is there in memory, we move the frame to front> // of queue> void> ReferencePage(Queue* queue, Hash* hash,> >unsigned pageNumber)> {> >QNode* reqPage = hash->matrix[sidenummer];> > >// the page is not in cache, bring it> >if> (reqPage == NULL)> >Enqueue(queue, hash, pageNumber);> > >// page is there and not at front, change pointer> >else> if> (reqPage != queue->foran) {> >// Unlink rquested page from its current location> >// in queue.> >reqPage->prev->next = reqPage->next;> >if> (reqPage->næste)> >reqPage->next->prev = reqPage->prev;> > >// If the requested page is rear, then change rear> >// as this node will be moved to front> >if> (reqPage == queue->bag) {> >queue->rear = reqPage->prev;> >queue->bag->næste = NULL;> >}> > >// Put the requested page before current front> >reqPage->næste = kø->front;> >reqPage->prev = NULL;> > >// Change prev of current front> >reqPage->next->prev = reqPage;> > >// Change front to the requested page> >queue->front = reqPage;> >}> }> > // Driver code> int> main()> {> >// Let cache can hold 4 pages> >Queue* q = createQueue(4);> > >// Let 10 different pages can be requested (pages to be> >// referenced are numbered from 0 to 9> >Hash* hash = createHash(10);> > >// Let us refer pages 1, 2, 3, 1, 4, 5> >ReferencePage(q, hash, 1);> >ReferencePage(q, hash, 2);> >ReferencePage(q, hash, 3);> >ReferencePage(q, hash, 1);> >ReferencePage(q, hash, 4);> >ReferencePage(q, hash, 5);> > >// Let us print cache frames after the above referenced> >// pages> >printf>(>'%d '>, q->forside->sidenummer);> >printf>(>'%d '>, q->forside->næste->sidenummer);> >printf>(>'%d '>, q->forside->næste->næste->sidenummer);> >printf>(>'%d '>, q->front->næste->næste->næste->sidenummer);> > >return> 0;> }> |
>
>
Java
/* We can use Java inbuilt Deque as a double> >ended queue to store the cache keys, with> >the descending time of reference from front> >to back and a set container to check presence> >of a key. But remove a key from the Deque using> >remove(), it takes O(N) time. This can be> >optimized by storing a reference (iterator) to> >each key in a hash map. */> import> java.util.Deque;> import> java.util.HashSet;> import> java.util.Iterator;> import> java.util.LinkedList;> > public> class> LRUCache {> > >// store keys of cache> >private> Deque doublyQueue;> > >// store references of key in cache> >private> HashSet hashSet;> > >// maximum capacity of cache> >private> final> int> CACHE_SIZE;> > >LRUCache(>int> capacity)> >{> >doublyQueue =>new> LinkedList();> >hashSet =>new> HashSet();> >CACHE_SIZE = capacity;> >}> > >/* Refer the page within the LRU cache */> >public> void> refer(>int> page)> >{> >if> (!hashSet.contains(page)) {> >if> (doublyQueue.size() == CACHE_SIZE) {> >int> last = doublyQueue.removeLast();> >hashSet.remove(last);> >}> >}> >else> {>/* The found page may not be always the last> >element, even if it's an intermediate> >element that needs to be removed and added> >to the start of the Queue */> >doublyQueue.remove(page);> >}> >doublyQueue.push(page);> >hashSet.add(page);> >}> > >// display contents of cache> >public> void> display()> >{> >Iterator itr = doublyQueue.iterator();> >while> (itr.hasNext()) {> >System.out.print(itr.next() +>' '>);> >}> >}> > >// Driver code> >public> static> void> main(String[] args)> >{> >LRUCache cache =>new> LRUCache(>4>);> >cache.refer(>1>);> >cache.refer(>2>);> >cache.refer(>3>);> >cache.refer(>1>);> >cache.refer(>4>);> >cache.refer(>5>);> >cache.display();> >}> }> // This code is contributed by Niraj Kumar> |
>
>
Python3
# We can use stl container list as a double> # ended queue to store the cache keys, with> # the descending time of reference from front> # to back and a set container to check presence> # of a key. But to fetch the address of the key> # in the list using find(), it takes O(N) time.> # This can be optimized by storing a reference> # (iterator) to each key in a hash map.> class> LRUCache:> ># store keys of cache> >def> __init__(>self>, n):> >self>.csize>=> n> >self>.dq>=> []> >self>.ma>=> {}> > > ># Refers key x with in the LRU cache> >def> refer(>self>, x):> > ># not present in cache> >if> x>not> in> self>.ma.keys():> ># cache is full> >if> len>(>self>.dq)>=>=> self>.csize:> ># delete least recently used element> >last>=> self>.dq[>->1>]> > ># Pops the last element> >ele>=> self>.dq.pop();> > ># Erase the last> >del> self>.ma[last]> > ># present in cache> >else>:> >del> self>.dq[>self>.ma[x]]> > ># update reference> >self>.dq.insert(>0>, x)> >self>.ma[x]>=> 0>;> > ># Function to display contents of cache> >def> display(>self>):> > ># Iterate in the deque and print> ># all the elements in it> >print>(>self>.dq)> > # Driver Code> ca>=> LRUCache(>4>)> > ca.refer(>1>)> ca.refer(>2>)> ca.refer(>3>)> ca.refer(>1>)> ca.refer(>4>)> ca.refer(>5>)> ca.display()> # This code is contributed by Satish Srinivas> |
>
>
C#
// C# program to implement the approach> > using> System;> using> System.Collections.Generic;> > class> LRUCache {> >// store keys of cache> >private> List<>int>>dobbeltkø;> > >// store references of key in cache> >private> HashSet<>int>>hashSet;> > >// maximum capacity of cache> >private> int> CACHE_SIZE;> > >public> LRUCache(>int> capacity)> >{> >doublyQueue =>new> List<>int>>();> >hashSet =>new> HashSet<>int>>();> >CACHE_SIZE = capacity;> >}> > >/* Refer the page within the LRU cache */> >public> void> Refer(>int> page)> >{> >if> (!hashSet.Contains(page)) {> >if> (doublyQueue.Count == CACHE_SIZE) {> >int> last> >= doublyQueue[doublyQueue.Count - 1];> >doublyQueue.RemoveAt(doublyQueue.Count - 1);> >hashSet.Remove(last);> >}> >}> >else> {> >/* The found page may not be always the last> >element, even if it's an intermediate> >element that needs to be removed and added> >to the start of the Queue */> >doublyQueue.Remove(page);> >}> >doublyQueue.Insert(0, page);> >hashSet.Add(page);> >}> > >// display contents of cache> >public> void> Display()> >{> >foreach>(>int> page>in> doublyQueue)> >{> >Console.Write(page +>' '>);> >}> >}> > >// Driver code> >static> void> Main(>string>[] args)> >{> >LRUCache cache =>new> LRUCache(4);> >cache.Refer(1);> >cache.Refer(2);> >cache.Refer(3);> >cache.Refer(1);> >cache.Refer(4);> >cache.Refer(5);> >cache.Display();> >}> }> > // This code is contributed by phasing17> |
>
>
Javascript
// JS code to implement the approach> class LRUCache {> >constructor(n) {> >this>.csize = n;> >this>.dq = [];> >this>.ma =>new> Map();> >}> > >refer(x) {> >if> (!>this>.ma.has(x)) {> >if> (>this>.dq.length ===>this>.csize) {> >const last =>this>.dq[>this>.dq.length - 1];> >this>.dq.pop();> >this>.ma.>delete>(last);> >}> >}>else> {> >this>.dq.splice(>this>.dq.indexOf(x), 1);> >}> > >this>.dq.unshift(x);> >this>.ma.set(x, 0);> >}> > >display() {> >console.log(>this>.dq);> >}> }> > const cache =>new> LRUCache(4);> > cache.refer(1);> cache.refer(2);> cache.refer(3);> cache.refer(1);> cache.refer(4);> cache.refer(5);> cache.display();> > // This code is contributed by phasing17> |
>
>
LRU-cache-implementering ved hjælp af dobbeltlinket liste og hashing :
Ideen er meget grundlæggende, dvs. bliv ved med at indsætte elementerne i hovedet.
- hvis elementet ikke er til stede på listen, skal du tilføje det til toppen af listen
- hvis elementet er til stede på listen, skal du flytte elementet til hovedet og flytte det resterende element på listen
Bemærk, at nodens prioritet vil afhænge af afstanden mellem noden og hovedet, jo tættest noden er på hovedet, jo højere prioritet har den. Så når Cache-størrelsen er fuld, og vi skal fjerne et eller andet element, fjerner vi elementet, der støder op til halen af den dobbeltforbundne liste.
LRU-cache-implementering ved hjælp af Deque & Hashmap:
Deque-datastruktur tillader indsættelse og sletning fra forsiden såvel som fra slutningen, denne egenskab muliggør implementering af LRU, da Front-element kan repræsentere højprioritetselement, mens slutelementet kan være lavprioritetselementet, dvs. Mindst nyligt brugt.
Arbejder:
- Få Operation : Kontrollerer, om nøglen findes i cachens hash-kort, og følg nedenstående tilfælde på deque:
- Hvis nøglen er fundet:
- Varen anses for at være brugt for nylig, så den flyttes til forsiden af deque.
- Værdien forbundet med nøglen returneres som resultatet af
get>operation.- Hvis nøglen ikke findes:
- returner -1 for at angive, at en sådan nøgle ikke er til stede.
- Put Operation: Tjek først, om nøglen allerede findes i cachens hash-kort, og følg nedenstående tilfælde på deque
- Hvis nøglen findes:
- Den værdi, der er knyttet til nøglen, opdateres.
- Genstanden flyttes til forsiden af deque, da den nu er den senest brugte.
- Hvis nøglen ikke findes:
- Hvis cachen er fuld, betyder det, at en ny genstand skal indsættes, og den mindst nyligt brugte genstand skal smides ud. Dette gøres ved at fjerne emnet fra slutningen af deque og den tilsvarende indtastning fra hash-kortet.
- Det nye nøgle-værdi-par indsættes derefter i både hash-kortet og forsiden af deque for at angive, at det er det senest brugte element
LRU-cache-implementering ved hjælp af Stack & Hashmap:
Implementering af en LRU (Least Recently Used) cache ved hjælp af en stak datastruktur og hashing kan være en smule vanskelig, fordi en simpel stak ikke giver effektiv adgang til det mindst nyligt brugte element. Du kan dog kombinere en stak med et hash-kort for at opnå dette effektivt. Her er en tilgang på højt niveau til at implementere det:
- Brug et Hash-kort : Hash-kortet gemmer nøgleværdi-parrene i cachen. Nøglerne vil afbildes til de tilsvarende noder i stakken.
- Brug en stak : Stakken vil bevare nøglerækkefølgen baseret på deres brug. Det senest brugte element vil være i bunden af stakken, og det senest brugte element vil være øverst
Denne tilgang er ikke så effektiv og bruges derfor ikke ofte.
LRU-cache ved hjælp af tællerimplementering:
Hver blok i cachen vil have sin egen LRU-tæller, hvor værdien af tælleren hører til {0 til n-1} , her ' n ' repræsenterer størrelsen af cachen. Blokken, der ændres under blokudskiftningen, bliver MRU-blokken, og som følge heraf ændres dens tællerværdi til n – 1. Tællerværdierne, der er større end den tilgåede bloks tællerværdi, dekrementeres med én. De resterende blokke er uændrede.
| Værdien af Conter | Prioritet | Brugt status |
|---|---|---|
| 0 | Lav | Sidst brugt |
| n-1 | Høj | Senest brugt |
LRU-cacheimplementering ved hjælp af Lazy Updates:
Implementering af en LRU (Least Recently Used) cache ved hjælp af dovne opdateringer er en almindelig teknik til at forbedre effektiviteten af cachens operationer. Dovne opdateringer involverer sporing af rækkefølgen, hvori der tilgås elementer uden øjeblikkelig opdatering af hele datastrukturen. Når der opstår en cache-miss, kan du beslutte, om du vil udføre en fuld opdatering baseret på nogle kriterier.
Kompleksitetsanalyse af LRU-cache:
- Tidskompleksitet:
- Put() operation: O(1) dvs. den tid, der kræves til at indsætte eller opdatere nyt nøgleværdi-par, er konstant
- Get() operation: O(1) dvs. den tid, der kræves for at få værdien af en nøgle, er konstant
- Hjælpeplads: O(N) hvor N er cachens kapacitet.
Fordele ved LRU-cache:
- Hurtig adgang : Det tager O(1) tid at få adgang til dataene fra LRU-cachen.
- Hurtig opdatering : Det tager O(1) tid at opdatere et nøgleværdi-par i LRU-cachen.
- Hurtig fjernelse af senest brugte data : Det kræver O(1) at slette det, der ikke er blevet brugt for nylig.
- Ingen tæsk: LRU er mindre modtagelig for tæsk sammenlignet med FIFO, fordi den tager hensyn til sidernes brugshistorik. Den kan registrere, hvilke sider der bruges ofte og prioritere dem til hukommelsesallokering, hvilket reducerer antallet af sidefejl og disk I/O-operationer.
Ulemper ved LRU-cache:
- Det kræver stor cachestørrelse for at øge effektiviteten.
- Det kræver yderligere datastruktur at blive implementeret.
- Hardwarehjælpen er høj.
- I LRU er fejldetektion vanskelig sammenlignet med andre algoritmer.
- Det har begrænset accept.
Real-World Anvendelse af LRU Cache:
- I databasesystemer for hurtige forespørgselsresultater.
- I operativsystemer for at minimere sidefejl.
- Teksteditorer og IDE'er til at gemme ofte brugte filer eller kodestykker
- Netværksroutere og switche bruger LRU til at øge effektiviteten af computernetværk
- I compiler-optimeringer
- Værktøjer til tekstforudsigelse og autofuldførelse