Som vi ved, kan Supervised Machine Learning-algoritmen bredt klassificeres i regression og klassifikationsalgoritmer. I regressionsalgoritmer har vi forudsagt output for kontinuerte værdier, men for at forudsige de kategoriske værdier har vi brug for klassifikationsalgoritmer.
Hvad er klassifikationsalgoritmen?
Klassifikationsalgoritmen er en Supervised Learning-teknik, der bruges til at identificere kategorien af nye observationer på basis af træningsdata. I Klassifikation lærer et program af det givne datasæt eller de givne observationer og klassificerer derefter ny observation i et antal klasser eller grupper. Såsom, Ja eller Nej, 0 eller 1, Spam eller Ikke Spam, kat eller hund, osv. Klasser kan kaldes som mål/etiketter eller kategorier.
java metoder
I modsætning til regression er outputvariablen for Klassifikation en kategori, ikke en værdi, såsom 'Grøn eller Blå', 'frugt eller dyr' osv. Da Klassifikationsalgoritmen er en overvåget læringsteknik, kræver den derfor mærkede inputdata, som betyder, at den indeholder input med det tilsvarende output.
I klassifikationsalgoritmen er en diskret outputfunktion(y) afbildet til inputvariabel(x).
y=f(x), where y = categorical output
Det bedste eksempel på en ML klassifikationsalgoritme er E-mail spam detektor .
Hovedformålet med klassifikationsalgoritmen er at identificere kategorien af et givent datasæt, og disse algoritmer bruges hovedsageligt til at forudsige output for de kategoriske data.
Klassificeringsalgoritmer kan bedre forstås ved hjælp af nedenstående diagram. I nedenstående diagram er der to klasser, klasse A og klasse B. Disse klasser har funktioner, der ligner hinanden og ikke ligner andre klasser.
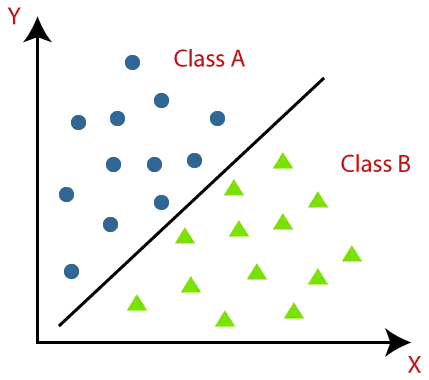
Algoritmen, der implementerer klassificeringen på et datasæt, er kendt som en klassifikator. Der er to typer klassifikationer:
Eksempler: JA eller NEJ, HAN eller KVIN, SPAM eller IKKE SPAM, KAT eller HUND osv.
Eksempel: Klassifikationer af typer af afgrøder, Klassifikation af typer af musik.
Elever i klassifikationsproblemer:
I klassifikationsopgaverne er der to typer elever:
Eksempel: K-NN algoritme, Case-baseret ræsonnement
Typer af ML-klassifikationsalgoritmer:
Klassifikationsalgoritmer kan yderligere opdeles i hovedsageligt to kategorier:
- Logistisk regression
- Support Vector Machines
- K-Nærmeste Naboer
- Kernel SVM
- Navne Bayes
- Klassifikation af beslutningstræ
- Tilfældig skovklassifikation
Bemærk: Vi vil lære ovenstående algoritmer i senere kapitler.
Evaluering af en klassifikationsmodel:
Når vores model er færdig, er det nødvendigt at evaluere dens ydeevne; enten er det en klassifikations- eller regressionsmodel. Så for at evaluere en klassifikationsmodel har vi følgende måder:
1. Logtab eller krydsentropitab:
- Det bruges til at evaluere ydeevnen af en klassifikator, hvis output er en sandsynlighedsværdi mellem 0 og 1.
- For en god binær klassifikationsmodel bør værdien af logtab være tæt på 0.
- Værdien af logtab stiger, hvis den forudsagte værdi afviger fra den faktiske værdi.
- Det lavere logtab repræsenterer modellens højere nøjagtighed.
- For binær klassificering kan krydsentropi beregnes som:
?(ylog(p)+(1?y)log(1?p))
Hvor y = Faktisk output, p = forudsagt output.
2. Forvirringsmatrix:
- Forvirringsmatricen giver os en matrix/tabel som output og beskriver modellens ydeevne.
- Det er også kendt som fejlmatrixen.
- Matricen består af forudsigelser resulterer i en opsummeret form, som har et samlet antal korrekte forudsigelser og ukorrekte forudsigelser. Matrixen ser ud som nedenstående tabel:
| Faktisk positiv | Faktisk negativ | |
|---|---|---|
| Forudsagt positiv | Ægte Positiv | Falsk positiv |
| Forudsagt negativ | Falsk negativ | Ægte negativ |

3. AUC-ROC kurve:
til loops java
- ROC kurve står for Modtagerens driftskarakteristikkurve og AUC står for Område under kurven .
- Det er en graf, der viser klassifikationsmodellens ydeevne ved forskellige tærskler.
- For at visualisere ydeevnen af multi-klasse klassifikationsmodellen bruger vi AUC-ROC kurven.
- ROC-kurven er plottet med TPR og FPR, hvor TPR (True Positive Rate) på Y-aksen og FPR (False Positive Rate) på X-aksen.
Brug eksempler på klassifikationsalgoritmer
Klassifikationsalgoritmer kan bruges forskellige steder. Nedenfor er nogle populære eksempler på brug af klassifikationsalgoritmer:
- E-mail Spam Detektion
- Tale genkendelse
- Identifikation af cancertumorceller.
- Klassificering af stoffer
- Biometrisk identifikation mv.