Før vi ser på forskellene mellem BFS og DFS, bør vi først vide om BFS og DFS separat.
Hvad er BFS?
BFS står for Breadth First Search . Det er også kendt som niveau ordregennemgang . Kødatastrukturen bruges til Breadth First Search-gennemgangen. Når vi bruger BFS-algoritmen til gennemgangen i en graf, kan vi betragte enhver knude som en rodknude.
Lad os overveje nedenstående graf for den første søgning i bredden.
java initialize array
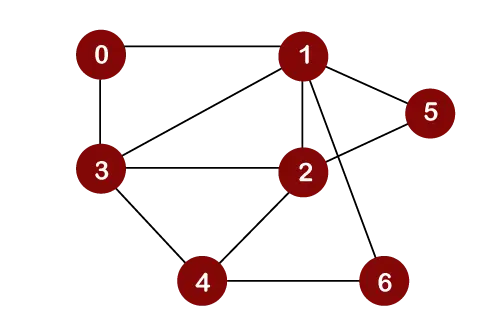
Antag, at vi betragter node 0 som en rodnode. Derfor vil gennemkørslen blive startet fra node 0.

Når node 0 er fjernet fra køen, bliver den udskrevet og markeret som en besøgt node.
Når node 0 er fjernet fra køen, vil de tilstødende noder af node 0 blive indsat i en kø som vist nedenfor:

Nu vil node 1 blive fjernet fra køen; den bliver udskrevet og markeret som en besøgt node
Når node 1 er fjernet fra køen, vil alle de tilstødende noder i en node 1 blive tilføjet i en kø. De tilstødende noder i node 1 er 0, 3, 2, 6 og 5. Men vi skal kun indsætte ubesøgte noder i en kø. Da knudepunkter 3, 2, 6 og 5 ikke er besøgt; derfor vil disse noder blive tilføjet i en kø som vist nedenfor:

Den næste node er 3 i en kø. Så node 3 vil blive fjernet fra køen, den bliver udskrevet og markeret som besøgt som vist nedenfor:

Når node 3 er fjernet fra køen, vil alle de tilstødende noder i node 3 undtagen de besøgte noder blive tilføjet i en kø. De tilstødende knudepunkter i knude 3 er 0, 1, 2 og 4. Da knudepunkter 0, 1 allerede er besøgt, og knude 2 er til stede i en kø; derfor skal vi kun indsætte node 4 i en kø.
hvad er målene på min computerskærm

Nu er den næste node i køen 2. Så 2 ville blive slettet fra køen. Det bliver udskrevet og markeret som besøgt som vist nedenfor:

Når node 2 er fjernet fra køen, vil alle de tilstødende noder i node 2 undtagen de besøgte noder blive tilføjet i en kø. De tilstødende knudepunkter i knudepunkt 2 er 1, 3, 5, 6 og 4. Da knudepunkterne 1 og 3 allerede er besøgt, og 4, 5, 6 allerede er tilføjet i køen; derfor behøver vi ikke at indsætte nogen node i køen.
Det næste element er 5. Så 5 ville blive slettet fra køen. Det bliver udskrevet og markeret som besøgt som vist nedenfor:

Når node 5 er fjernet fra køen, vil alle de tilstødende noder i node 5 undtagen de besøgte noder blive tilføjet i køen. De tilstødende noder af node 5 er 1 og 2. Da begge noder allerede er besøgt; derfor er der ingen top, der skal indsættes i en kø.
Den næste node er 6. Så 6 ville blive slettet fra køen. Det bliver udskrevet og markeret som besøgt som vist nedenfor:

Når noden 6 er fjernet fra køen, vil alle de tilstødende noder i node 6, undtagen de besøgte noder, blive tilføjet i køen. De tilstødende knudepunkter i knudepunkt 6 er 1 og 4. Da knudepunkt 1 allerede er besøgt, og knudepunkt 4 allerede er tilføjet i køen; derfor er der ikke et toppunkt, der skal indsættes i køen.
Det næste element i køen er 4. Så 4 ville blive slettet fra køen. Det bliver udskrevet og markeret som besøgt.
Når node 4 er fjernet fra køen, vil alle de tilstødende noder på node 4 undtagen de besøgte noder blive tilføjet i køen. De tilstødende noder af node 4 er 3, 2 og 6. Da alle de tilstødende noder allerede er besøgt; så der er ingen top, der skal indsættes i køen.
Hvad er DFS?
DFS står for Depth First Search. Ved DFS-traversal anvendes stakdatastrukturen, som fungerer efter LIFO-princippet (Last In First Out). I DFS kan traversering startes fra enhver knude, eller vi kan sige, at enhver knude kan betragtes som en rodknude, indtil rodknuden ikke er nævnt i opgaven.
I tilfælde af BFS, det element, der slettes fra køen, tilføjes de tilstødende knudepunkter i den slettede knude til køen. I modsætning hertil, i DFS, det element, der fjernes fra stakken, tilføjes kun én tilstødende node af en slettet node i stakken.
skal sortere
Lad os overveje nedenstående graf for gennemgangen af Depth First Search.

Betragt node 0 som en rodnode.
Først indsætter vi elementet 0 i stakken som vist nedenfor:

Knudepunktet 0 har to tilstødende knudepunkter, dvs. 1 og 3. Nu kan vi kun tage én tilstødende knude, enten 1 eller 3, til at krydse. Antag, at vi betragter node 1; derfor indsættes 1 i en stak og udskrives som vist nedenfor:

Nu vil vi se på de tilstødende knudepunkter i knude 1. De ubesøgte tilstødende knudepunkter i knude 1 er 3, 2, 5 og 6. Vi kan betragte enhver af disse fire spidser. Antag, at vi tager node 3 og indsætter den i stakken som vist nedenfor:

Overvej de ubesøgte tilstødende hjørner af knude 3. De ubesøgte tilstødende knudepunkter i knude 3 er 2 og 4. Vi kan tage begge spidser, dvs. 2 eller 4. Antag, at vi tager top 2 og indsætter det i stakken som vist nedenfor:

De ubesøgte tilstødende hjørner af knude 2 er 5 og 4. Vi kan vælge en af knudepunkterne, dvs. 5 eller 4. Antag, at vi tager top 4 og indsætter i stakken som vist nedenfor:
heltal til streng i java

Nu vil vi overveje de ubesøgte tilstødende toppunkter af node 4. Det ubesøgte tilstødende toppunkt af node 4 er node 6. Derfor indsættes element 6 i stakken som vist nedenfor:

Efter at have indsat element 6 i stakken, vil vi se på de ubesøgte tilstødende hjørner af knude 6. Da der ikke er nogen ubesøgte tilstødende knudepunkter i knude 6, så kan vi ikke bevæge os ud over knude 6. I dette tilfælde vil vi udføre tilbagesporing . Det øverste element, dvs. 6, ville blive trukket ud fra stakken som vist nedenfor:


Det øverste element i stakken er 4. Da der ikke er nogen ubesøgte tilstødende hjørner tilbage af node 4; derfor er node 4 poppet ud af stakken som vist nedenfor:


Det næstøverste element i stakken er 2. Nu vil vi se på de ubesøgte tilstødende knudepunkter for knude 2. Da kun én ubesøgt knude, dvs. 5 er tilbage, vil knude 5 blive skubbet ind i stakken over 2 og blive udskrevet som vist nedenfor:

Nu vil vi kontrollere de tilstødende hjørner af node 5, som stadig er ubesøgte. Da der ikke er noget toppunkt tilbage, der skal besøges, så vipper vi element 5 fra stakken som vist nedenfor:
bygherre design mønster

Vi kan ikke rykke yderligere 5, så vi er nødt til at udføre backtracking. Ved backtracking ville det øverste element blive trukket ud fra stakken. Det øverste element er 5, der ville blive poppet ud fra stakken, og vi flytter tilbage til node 2 som vist nedenfor:

Nu vil vi kontrollere de ubesøgte tilstødende hjørner af node 2. Da der ikke er noget tilstødende hjørne, der skal besøges, så udfører vi tilbagesporing. I backtracking ville det øverste element, dvs. 2 blive poppet ud fra stakken, og vi flytter tilbage til node 3 som vist nedenfor:


Nu vil vi kontrollere de ubesøgte tilstødende hjørner af node 3. Da der ikke er noget tilstødende hjørne, der skal besøges, så udfører vi tilbagesporing. I backtracking ville det øverste element, dvs. 3 blive poppet ud fra stakken, og vi flytter tilbage til node 1 som vist nedenfor:


Efter at have poppet element 3 ud, vil vi kontrollere de ubesøgte tilstødende toppunkter af node 1. Da der ikke er noget toppunkt tilbage at besøge; derfor vil tilbagesporingen blive udført. I backtracking ville det øverste element, dvs. 1 blive poppet ud fra stakken, og vi flytter tilbage til node 0 som vist nedenfor:


Vi vil kontrollere de tilstødende hjørner af node 0, som stadig er ubesøgte. Da der ikke er noget tilstødende vertex tilbage, der skal besøges, så vi udfører backtracking. I dette ville kun ét element, dvs. 0 tilbage i stakken, blive poppet ud fra stakken som vist nedenfor:

Som vi kan se i ovenstående figur, er stakken tom. Så vi er nødt til at stoppe DFS-gennemgangen her, og de elementer, der udskrives, er resultatet af DFS-gennemgangen.
Forskelle mellem BFS og DFS
Følgende er forskellene mellem BFS og DFS:
| BFS | DFS | |
|---|---|---|
| Fuld form | BFS står for Breadth First Search. | DFS står for Depth First Search. |
| Teknik | Det er en toppunktsbaseret teknik til at finde den korteste vej i en graf. | Det er en kantbaseret teknik, fordi hjørnerne langs kanten udforskes først fra start- til slutknudepunktet. |
| Definition | BFS er en gennemløbsteknik, hvor alle noder på samme niveau udforskes først, og derefter går vi til næste niveau. | DFS er også en traversalteknik, hvor traversering startes fra rodknuden og udforske knudepunkterne så langt som muligt, indtil vi når knudepunktet, der ikke har nogen ubesøgte tilstødende knudepunkter. |
| Datastruktur | Kødatastruktur bruges til BFS-gennemgangen. | Stakdatastrukturen bruges til BFS-gennemgangen. |
| Backtracking | BFS bruger ikke backtracking-konceptet. | DFS bruger backtracking til at krydse alle de ubesøgte noder. |
| Antal kanter | BFS finder den korteste vej med et minimum antal kanter at krydse fra kilden til destinationspunktet. | I DFS kræves der et større antal kanter for at krydse fra kildepunktet til destinationspunktet. |
| Optimalitet | BFS-traversering er optimal for de toppunkter, der skal søges tættere på kildens toppunkt. | DFS-traversering er optimal for de grafer, hvor løsninger er væk fra kildepunktet. |
| Fart | BFS er langsommere end DFS. | DFS er hurtigere end BFS. |
| Egnethed til beslutningstræ | Det er ikke egnet til beslutningstræet, fordi det kræver at udforske alle naboknuderne først. | Det er velegnet til beslutningstræet. På baggrund af beslutningen udforsker den alle veje. Når målet er fundet, stopper det sin gennemkøring. |
| Hukommelseseffektiv | Det er ikke hukommelseseffektivt, da det kræver mere hukommelse end DFS. | Det er hukommelseseffektivt, da det kræver mindre hukommelse end BFS. |