Vi læser de lineære datastrukturer som en matrix, sammenkædet liste, stak og kø, hvor alle elementer er arrangeret på en sekventiel måde. De forskellige datastrukturer bruges til forskellige slags data.
Nogle faktorer tages i betragtning ved valg af datastruktur:
Et træ er også en af de datastrukturer, der repræsenterer hierarkiske data. Antag, at vi ønsker at vise medarbejderne og deres positioner i hierarkisk form, så kan det repræsenteres som vist nedenfor:
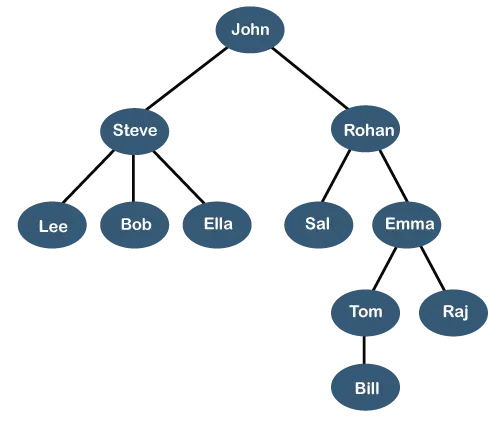
Ovenstående træ viser organisationshierarki af et eller andet selskab. I ovenstående struktur, John er direktør af virksomheden, og John har to direkte rapporter navngivet som Steve og Rohan . Steve har tre direkte rapporter nævnt Lee, Bob, Ella hvor Steve er leder. Bob har to direkte rapporter nævnt Skal og Emma . Emma har to direkte rapporter navngivet Tom og Raj . Tom har én direkte rapport navngivet Regning . Denne særlige logiske struktur er kendt som en Træ . Dens struktur ligner det rigtige træ, så det hedder en Træ . I denne struktur er rod er øverst, og dens grene bevæger sig i nedadgående retning. Derfor kan vi sige, at træets datastruktur er en effektiv måde at gemme dataene på en hierarkisk måde.
Lad os forstå nogle nøglepunkter i trædatastrukturen.
forbindelse java mysql
- En trædatastruktur er defineret som en samling af objekter eller enheder kendt som noder, der er forbundet med hinanden for at repræsentere eller simulere hierarki.
- En trædatastruktur er en ikke-lineær datastruktur, fordi den ikke gemmer på en sekventiel måde. Det er en hierarkisk struktur, da elementer i et træ er arrangeret i flere niveauer.
- I trædatastrukturen er den øverste knude kendt som en rodknude. Hver node indeholder nogle data, og data kan være af enhver type. I ovenstående træstruktur indeholder noden navnet på medarbejderen, så datatypen ville være en streng.
- Hver node indeholder nogle data og linket eller referencen til andre noder, der kan kaldes børn.
Nogle grundlæggende udtryk, der bruges i trædatastruktur.
Lad os overveje træstrukturen, som er vist nedenfor:

I ovenstående struktur er hver node mærket med et eller andet nummer. Hver pil vist i ovenstående figur er kendt som en link mellem de to knudepunkter.
Egenskaber for trædatastruktur

Baseret på egenskaberne for trædatastrukturen klassificeres træer i forskellige kategorier.
Implementering af træ
Trædatastrukturen kan skabes ved at skabe noderne dynamisk ved hjælp af pointerne. Træet i hukommelsen kan repræsenteres som vist nedenfor:

Ovenstående figur viser repræsentationen af trædatastrukturen i hukommelsen. I ovenstående struktur indeholder noden tre felter. Det andet felt gemmer dataene; det første felt gemmer adressen på det venstre barn, og det tredje felt gemmer adressen på det højre barn.
I programmering kan strukturen af en node defineres som:
struct node { int data; struct node *left; struct node *right; } Ovenstående struktur kan kun defineres for de binære træer, fordi det binære træ kan have højst to børn, og generiske træer kan have mere end to børn. Strukturen af noden for generiske træer ville være anderledes sammenlignet med det binære træ.
Anvendelse af træer
Følgende er anvendelserne af træer:
konstruktører i java
Typer af trædatastruktur
Følgende er typerne af en trædatastruktur:

Der kan være n antal undertræer i et generelt træ. I det generelle træ er undertræerne uordnede, da noderne i undertræet ikke kan sorteres.
Hvert ikke-tomt træ har en nedadgående kant, og disse kanter er forbundet med de noder, der er kendt som børneknuder . Rodknuden er mærket med niveau 0. De knudepunkter, der har samme forælder, er kendt som søskende .

For at vide mere om det binære træ, klik på linket nedenfor:
https://www.javatpoint.com/binary-tree
Hver knude i det venstre undertræ skal indeholde en værdi, der er mindre end værdien af rodknuden, og værdien af hver knude i det højre undertræ skal være større end værdien af rodknuden.
En node kan oprettes ved hjælp af en brugerdefineret datatype kendt som struktur, som vist nedenfor:
struct node { int data; struct node *left; struct node *right; } Ovenstående er nodestrukturen med tre felter: datafelt, det andet felt er den venstre pointer af nodetypen, og det tredje felt er nodetypens højre pointer.
For at vide mere om det binære søgetræ, klik på linket nedenfor:
https://www.javatpoint.com/binary-search-tree
Det er en af typerne af det binære træ, eller vi kan sige, at det er en variant af det binære søgetræ. AVL-træet opfylder ejendommens ejendom binært træ samt af binært søgetræ . Det er et selvbalancerende binært søgetræ, der blev opfundet af Adelson Velsky Lindas . Her betyder selvbalancering, at afbalancering af højderne af venstre undertræ og højre undertræ. Denne balancering måles i forhold til balanceringsfaktor .
Vi kan betragte et træ som et AVL-træ, hvis træet adlyder det binære søgetræ samt en balanceringsfaktor. Balancefaktoren kan defineres som forskellen mellem højden af venstre undertræ og højden af højre undertræ . Balancefaktorens værdi skal være enten 0, -1 eller 1; derfor bør hver node i AVL-træet have værdien af balancefaktoren enten som 0, -1 eller 1.
For at vide mere om AVL-træet, klik på linket nedenfor:
https://www.javatpoint.com/avl-tree
Det rød-sorte træ er det binære søgetræ. Forudsætningen for det rød-sort træ er, at vi skal kende til det binære søgetræ. I et binært søgetræ skal værdien af det venstre undertræ være mindre end værdien af den node, og værdien af det højre undertræ skal være større end værdien af det knudepunkt. Som vi ved, at tidskompleksiteten af binær søgning i det gennemsnitlige tilfælde er log2n, det bedste tilfælde er O(1), og det værste tilfælde er O(n).
java input
Når en operation udføres på træet, ønsker vi, at vores træ skal være afbalanceret, så alle operationer som søgning, indsættelse, sletning osv. tager kortere tid, og alle disse operationer vil have samme tidskompleksitet som log2n.
Det rød-sorte træ er et selvbalancerende binært søgetræ. AVL-træet er da også et højdebalancerende binært søgetræ hvorfor kræver vi et rød-sort træ . I AVL-træet ved vi ikke, hvor mange rotationer der skal til for at balancere træet, men i det rød-sorte træ kræves der maksimalt 2 rotationer for at balancere træet. Den indeholder en ekstra bit, der repræsenterer enten den røde eller sorte farve af en node for at sikre balancen af træet.
Splay-træets datastruktur er også et binært søgetræ, hvor det nyligt tilgåede element placeres ved træets rodposition ved at udføre nogle rotationsoperationer. Her, spredning betyder den nyligt tilgåede node. Det er en selvbalancerende binært søgetræ, der ikke har nogen eksplicit balancebetingelse som AVL træ.
Det kan være en mulighed, at højden af splay-træet ikke er afbalanceret, dvs. højden af både venstre og højre undertræ kan variere, men operationerne i splay-træet tager rækkefølgen af berolige tid hvor n er antallet af noder.
Splay tree er et balanceret træ, men det kan ikke betragtes som et højdebalanceret træ, fordi der efter hver operation udføres rotation, hvilket fører til et balanceret træ.
Treap-datastrukturen kom fra Tree and Heap-datastrukturen. Så det omfatter egenskaberne for både træ- og heap-datastrukturer. I binært søgetræ skal hver knude på det venstre undertræ være lig med eller mindre end værdien af rodknuden, og hver knude på det højre undertræ skal være lig med eller større end værdien af rodknuden. I heap-datastrukturen indeholder både højre og venstre undertræer større nøgler end roden; derfor kan vi sige, at rodnoden indeholder den laveste værdi.
I treap-datastrukturen har hver node begge dele nøgle og prioritet hvor nøglen er afledt fra det binære søgetræ, og prioritet er afledt fra heap-datastrukturen.
Det Treap datastrukturen følger to egenskaber, som er angivet nedenfor:
- Højre underordnede af en knude>=aktuel knude og venstre underordnede af en knude<=current node (binary tree)< li>
- Børn af ethvert undertræ skal være større end noden (heapen)
B-træet er et balanceret m-vej træ hvor m definerer rækkefølgen af træet. Indtil nu har vi læst, at noden kun indeholder én nøgle, men b-tree kan have mere end én nøgle og mere end 2 børn. Det vedligeholder altid de sorterede data. I binært træ er det muligt, at bladknuder kan være på forskellige niveauer, men i b-træ skal alle bladknuder være på samme niveau.
Hvis rækkefølgen er m, har node følgende egenskaber:
- Hver node i et b-træ kan have maksimum m børn
- For minimum børn har en bladknude 0 børn, rodknude har minimum 2 børn og intern node har minimum loft på m/2 børn. For eksempel er værdien af m 5, hvilket betyder, at en node kan have 5 børn, og interne noder kan maksimalt indeholde 3 børn.
- Hver node har maksimale (m-1) nøgler.
Rodnoden skal indeholde minimum 1 nøgle, og alle andre noder skal indeholde mindst loft på m/2 minus 1 nøgler.