Introduktion:
URL-forkortere er et eksempel på hashing, da det kortlægger stor størrelse URL til lille størrelse
Nogle eksempler på hash-funktioner:
- nøgle % antal spande
- ASCII-værdi af karakter * PrimeNumberx. Hvor x = 1, 2, 3….n
- Du kan lave din egen hash-funktion, men det bør være en god hash-funktion, der giver færre antal kollisioner.
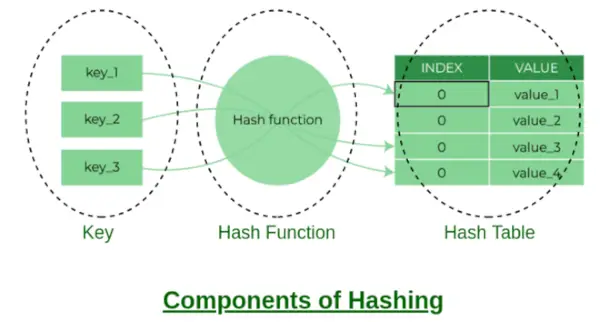
Komponenter af hashing
Bucket Index:
Den værdi, der returneres af Hash-funktionen, er bucket-indekset for en nøgle i en separat kædemetode. Hvert indeks i arrayet kaldes en bucket, da det er en bucket af en linket liste.
Genhasning:
Rehashing er et koncept, der reducerer kollision, når elementerne øges i den aktuelle hash-tabel. Det vil lave et nyt array med fordoblet størrelse og kopiere de tidligere array-elementer til det, og det er ligesom vektorens interne arbejde i C++. Det er klart, at Hash-funktionen skal være dynamisk, da den skal afspejle nogle ændringer, når kapaciteten øges. Hash-funktionen inkluderer kapaciteten af hash-tabellen i den, derfor, mens kopiering af nøgleværdier fra den tidligere array-hash-funktion giver forskellige bucket-indekser, da den er afhængig af kapaciteten (buckets) af hash-tabellen. Generelt, når værdien af belastningsfaktoren er større end 0,5 udføres omhasninger.
- Dobbelt størrelse af arrayet.
- Kopier elementerne fra det forrige array til det nye array. Vi bruger hash-funktionen, mens vi kopierer hver node til et nyt array igen, derfor vil det reducere kollision.
- Slet det forrige array fra hukommelsen, og peg dit hash-korts indvendige array-markør til dette nye array.
- Generelt er Load Factor = antal elementer i Hash Map / samlet antal buckets (kapacitet).
Kollision:
Kollision er den situation, hvor skovlindekset ikke er tomt. Det betyder, at et linket listehoved er til stede ved det bucket-indeks. Vi har to eller flere værdier, der knytter sig til det samme bucket-indeks.
Vigtigste funktioner i vores program
- Indskud
- Søg
- Hash funktion
- Slet
- Genhasning
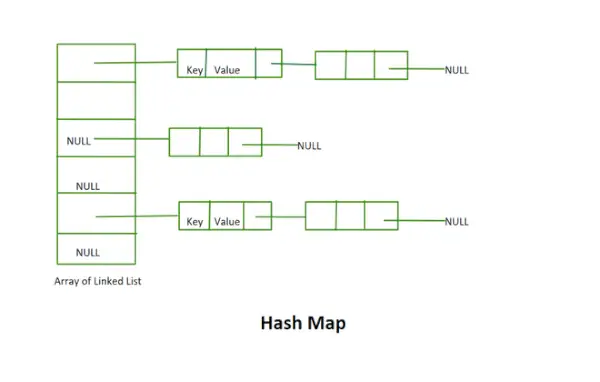
Hash kort
Implementering uden rehashing:
C
hvordan man sorterer et array i java
hvordan man finder skærmstørrelse
#include> #include> #include> // Linked List node> struct> node {> >// key is string> >char>* key;> >// value is also string> >char>* value;> >struct> node* next;> };> // like constructor> void> setNode(>struct> node* node,>char>* key,>char>* value)> {> >node->nøgle = nøgle;> >node->værdi = værdi;> >node->næste = NULL;> >return>;> };> struct> hashMap {> >// Current number of elements in hashMap> >// and capacity of hashMap> >int> numOfElements, capacity;> >// hold base address array of linked list> >struct> node** arr;> };> // like constructor> void> initializeHashMap(>struct> hashMap* mp)> {> >// Default capacity in this case> >mp->kapacitet = 100;> >mp->numOfElements = 0;> >// array of size = 1> >mp->arr = (>struct> node**)>malloc>(>sizeof>(>struct> node*)> >* mp->kapacitet);> >return>;> }> int> hashFunction(>struct> hashMap* mp,>char>* key)> {> >int> bucketIndex;> >int> sum = 0, factor = 31;> >for> (>int> i = 0; i <>strlen>(key); i++) {> >// sum = sum + (ascii value of> >// char * (primeNumber ^ x))...> >// where x = 1, 2, 3....n> >sum = ((sum % mp->kapacitet)> >+ (((>int>)key[i]) * factor) % mp->kapacitet)> >% mp->kapacitet;> >// factor = factor * prime> >// number....(prime> >// number) ^ x> >factor = ((factor % __INT16_MAX__)> >* (31 % __INT16_MAX__))> >% __INT16_MAX__;> >}> >bucketIndex = sum;> >return> bucketIndex;> }> void> insert(>struct> hashMap* mp,>char>* key,>char>* value)> {> >// Getting bucket index for the given> >// key - value pair> >int> bucketIndex = hashFunction(mp, key);> >struct> node* newNode = (>struct> node*)>malloc>(> >// Creating a new node> >sizeof>(>struct> node));> >// Setting value of node> >setNode(newNode, key, value);> >// Bucket index is empty....no collision> >if> (mp->arr[bucketIndex] == NULL) {> >mp->arr[bucketIndex] = nyNode;> >}> >// Collision> >else> {> >// Adding newNode at the head of> >// linked list which is present> >// at bucket index....insertion at> >// head in linked list> >newNode->næste = mp->arr[bucketIndex];> >mp->arr[bucketIndex] = nyNode;> >}> >return>;> }> void> delete> (>struct> hashMap* mp,>char>* key)> {> >// Getting bucket index for the> >// given key> >int> bucketIndex = hashFunction(mp, key);> >struct> node* prevNode = NULL;> >// Points to the head of> >// linked list present at> >// bucket index> >struct> node* currNode = mp->arr[bucketIndex];> >while> (currNode != NULL) {> >// Key is matched at delete this> >// node from linked list> >if> (>strcmp>(key, currNode->nøgle) == 0) {> >// Head node> >// deletion> >if> (currNode == mp->arr[bucketIndex]) {> >mp->arr[bucketIndex] = currNode->næste;> >}> >// Last node or middle node> >else> {> >prevNode->næste = currNode->næste;> >}> >free>(currNode);> >break>;> >}> >prevNode = currNode;> >currNode = currNode->næste;> >}> >return>;> }> char>* search(>struct> hashMap* mp,>char>* key)> {> >// Getting the bucket index> >// for the given key> >int> bucketIndex = hashFunction(mp, key);> >// Head of the linked list> >// present at bucket index> >struct> node* bucketHead = mp->arr[bucketIndex];> >while> (bucketHead != NULL) {> >// Key is found in the hashMap> >if> (bucketHead->tast == tast) {> >return> bucketHead->værdi;> >}> >bucketHead = bucketHead->næste;> >}> >// If no key found in the hashMap> >// equal to the given key> >char>* errorMssg = (>char>*)>malloc>(>sizeof>(>char>) * 25);> >errorMssg =>'Oops! No data found.
'>;> >return> errorMssg;> }> // Drivers code> int> main()> {> >// Initialize the value of mp> >struct> hashMap* mp> >= (>struct> hashMap*)>malloc>(>sizeof>(>struct> hashMap));> >initializeHashMap(mp);> >insert(mp,>'Yogaholic'>,>'Anjali'>);> >insert(mp,>'pluto14'>,>'Vartika'>);> >insert(mp,>'elite_Programmer'>,>'Manish'>);> >insert(mp,>'GFG'>,>'techcodeview.com'>);> >insert(mp,>'decentBoy'>,>'Mayank'>);> >printf>(>'%s
'>, search(mp,>'elite_Programmer'>));> >printf>(>'%s
'>, search(mp,>'Yogaholic'>));> >printf>(>'%s
'>, search(mp,>'pluto14'>));> >printf>(>'%s
'>, search(mp,>'decentBoy'>));> >printf>(>'%s
'>, search(mp,>'GFG'>));> >// Key is not inserted> >printf>(>'%s
'>, search(mp,>'randomKey'>));> >printf>(>'
After deletion :
'>);> >// Deletion of key> >delete> (mp,>'decentBoy'>);> >printf>(>'%s
'>, search(mp,>'decentBoy'>));> >return> 0;> }> |
>
>
C++
forskel på kærlighed og lide
#include> #include> // Linked List node> struct> node {> >// key is string> >char>* key;> >// value is also string> >char>* value;> >struct> node* next;> };> // like constructor> void> setNode(>struct> node* node,>char>* key,>char>* value) {> >node->nøgle = nøgle;> >node->værdi = værdi;> >node->næste = NULL;> >return>;> }> struct> hashMap {> >// Current number of elements in hashMap> >// and capacity of hashMap> >int> numOfElements, capacity;> >// hold base address array of linked list> >struct> node** arr;> };> // like constructor> void> initializeHashMap(>struct> hashMap* mp) {> >// Default capacity in this case> >mp->kapacitet = 100;> >mp->numOfElements = 0;> >// array of size = 1> >mp->arr = (>struct> node**)>malloc>(>sizeof>(>struct> node*) * mp->kapacitet);> >return>;> }> int> hashFunction(>struct> hashMap* mp,>char>* key) {> >int> bucketIndex;> >int> sum = 0, factor = 31;> >for> (>int> i = 0; i <>strlen>(key); i++) {> >// sum = sum + (ascii value of> >// char * (primeNumber ^ x))...> >// where x = 1, 2, 3....n> >sum = ((sum % mp->kapacitet) + (((>int>)key[i]) * factor) % mp->kapacitet) % mp->kapacitet;> >// factor = factor * prime> >// number....(prime> >// number) ^ x> >factor = ((factor % __INT16_MAX__) * (31 % __INT16_MAX__)) % __INT16_MAX__;> >}> >bucketIndex = sum;> >return> bucketIndex;> }> void> insert(>struct> hashMap* mp,>char>* key,>char>* value) {> >// Getting bucket index for the given> >// key - value pair> >int> bucketIndex = hashFunction(mp, key);> >struct> node* newNode = (>struct> node*)>malloc>(> >// Creating a new node> >sizeof>(>struct> node));> >// Setting value of node> >setNode(newNode, key, value);> >// Bucket index is empty....no collision> >if> (mp->arr[bucketIndex] == NULL) {> >mp->arr[bucketIndex] = newNode;> >}> >// Collision> >else> {> >// Adding newNode at the head of> >// linked list which is present> >// at bucket index....insertion at> >// head in linked list> >newNode->næste = mp->arr[bucketIndex];> >mp->arr[bucketIndex] = newNode;> >}> >return>;> }> void> deleteKey(>struct> hashMap* mp,>char>* key) {> >// Getting bucket index for the> >// given key> >int> bucketIndex = hashFunction(mp, key);> >struct> node* prevNode = NULL;> >// Points to the head of> >// linked list present at> >// bucket index> >struct> node* currNode = mp->arr[bucketIndex];> >while> (currNode != NULL) {> >// Key is matched at delete this> >// node from linked list> >if> (>strcmp>(key, currNode->tast) == 0) {> >// Head node> >// deletion> >if> (currNode == mp->arr[bucketIndex]) {> >mp->arr[bucketIndex] = currNode->næste;> >}> >// Last node or middle node> >else> {> >prevNode->næste = currNode->næste;> }> free>(currNode);> break>;> }> prevNode = currNode;> >currNode = currNode->næste;> >}> return>;> }> char>* search(>struct> hashMap* mp,>char>* key) {> // Getting the bucket index for the given key> int> bucketIndex = hashFunction(mp, key);> // Head of the linked list present at bucket index> struct> node* bucketHead = mp->arr[bucketIndex];> while> (bucketHead != NULL) {> > >// Key is found in the hashMap> >if> (>strcmp>(bucketHead->tast, tast) == 0) {> >return> bucketHead->værdi;> >}> > >bucketHead = bucketHead->næste;> }> // If no key found in the hashMap equal to the given key> char>* errorMssg = (>char>*)>malloc>(>sizeof>(>char>) * 25);> strcpy>(errorMssg,>'Oops! No data found.
'>);> return> errorMssg;> }> // Drivers code> int> main()> {> // Initialize the value of mp> struct> hashMap* mp = (>struct> hashMap*)>malloc>(>sizeof>(>struct> hashMap));> initializeHashMap(mp);> insert(mp,>'Yogaholic'>,>'Anjali'>);> insert(mp,>'pluto14'>,>'Vartika'>);> insert(mp,>'elite_Programmer'>,>'Manish'>);> insert(mp,>'GFG'>,>'techcodeview.com'>);> insert(mp,>'decentBoy'>,>'Mayank'>);> printf>(>'%s
'>, search(mp,>'elite_Programmer'>));> printf>(>'%s
'>, search(mp,>'Yogaholic'>));> printf>(>'%s
'>, search(mp,>'pluto14'>));> printf>(>'%s
'>, search(mp,>'decentBoy'>));> printf>(>'%s
'>, search(mp,>'GFG'>));> // Key is not inserted> printf>(>'%s
'>, search(mp,>'randomKey'>));> printf>(>'
After deletion :
'>);> // Deletion of key> deleteKey(mp,>'decentBoy'>);> // Searching the deleted key> printf>(>'%s
'>, search(mp,>'decentBoy'>));> return> 0;> }> |
>
>Produktion
Manish Anjali Vartika Mayank techcodeview.com Oops! No data found. After deletion : Oops! No data found.>
Forklaring:
- insertion: Indsætter nøgleværdi-parret i spidsen af en linket liste, som er til stede ved det givne bucket-indeks. hashFunction: Giver bucket-indekset for den givne nøgle. Vores hash-funktion = ASCII-værdi af karakter * primeNumberx . Primtallet i vores tilfælde er 31, og værdien af x er stigende fra 1 til n for på hinanden følgende tegn i en nøgle. sletning: Sletter nøgle-værdi-par fra hash-tabellen for den givne nøgle. Det sletter noden fra den sammenkædede liste, som indeholder nøgleværdi-parret. Søg: Søg efter værdien af den givne nøgle.
- Denne implementering bruger ikke rehashing-konceptet. Det er en række af sammenkædede lister i fast størrelse.
- Nøgle og værdi er begge strenge i det givne eksempel.
Tidskompleksitet og rumkompleksitet:
Tidskompleksiteten af hash tabel indsættelse og sletning operationer er O(1) i gennemsnit. Der er nogle matematiske beregninger, der beviser det.
- Tidskompleksitet ved indsættelse: I gennemsnitstilfældet er den konstant. I værste fald er det lineært. Tidskompleksitet af søgning: I gennemsnitstilfældet er den konstant. I værste fald er det lineært. Tidskompleksitet for sletning: I gennemsnitlige tilfælde er den konstant. I værste fald er det lineært. Rumkompleksitet: O(n), da det har n antal elementer.
Relaterede artikler:
- Separat kædesammenstødshåndteringsteknik i hashing.