Et databaseskema er en struktur, der repræsenterer den logiske lagring af data i en database . Det repræsenterer organiseringen af data og giver information om relationerne mellem tabellerne i en given database. I dette emne vil vi forstå mere om databaseskema og dets typer. Før vi forstår databaseskemaet, lad os først forstå, hvad en database er.
Hvad er database?
EN database er et sted at opbevare information. Det kan gemme de enkleste data, såsom en liste over personer såvel som de mest komplekse data. Databasen gemmer oplysningerne i et velstruktureret format.
Hvad er databaseskema?
- Et databaseskema er den logiske repræsentation af en database, som viser, hvordan dataene er lagret logisk i hele databasen. Den indeholder en liste over attributter og instruktioner, der informerer databasemotoren om, hvordan data er organiseret, og hvordan elementerne er relateret til hinanden.
- Et databaseskema indeholder skemaobjekter, der kan omfatte tabeller, felter, pakker, visninger, relationer, primærnøgle, fremmednøgle,
- I virkeligheden er dataene fysisk gemt i filer, der kan være i ustruktureret form, men for at hente dem og bruge dem, er vi nødt til at sætte dem i en struktureret form. For at gøre dette bruges et databaseskema. Det giver viden om, hvordan data er organiseret i en database, og hvordan det er forbundet med andre data.
- Et databaseskemaobjekt indeholder følgende:
- Konsekvent formatering for alle dataindtastninger.
- Databaseobjekter og unikke nøgler til alle dataindtastninger.
- Tabeller med flere kolonner, og hver kolonne indeholder sit navn og datatype.
- Kompleksiteten og størrelsen af skemaet varierer afhængigt af projektets størrelse. Det hjælper udviklere med nemt at administrere og strukturere databasen, før den koder den.
- Det givne diagram er et eksempel på et databaseskema. Den indeholder tre tabeller, deres datatyper. Dette repræsenterer også relationerne mellem tabellerne og primærnøgler samt fremmednøgler.
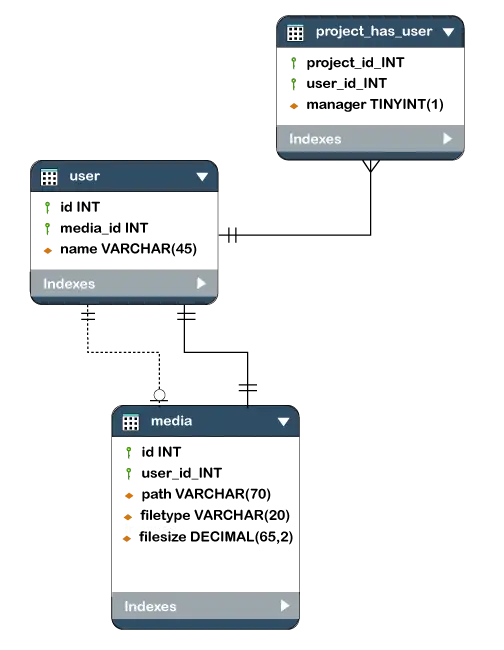
Typer af databaseskema
Databaseskemaet er opdelt i tre typer, som er:

1. Fysisk databaseskema
Et fysisk databaseskema angiver, hvordan data lagres fysisk på et lagersystem eller disklager i form af filer og indekser. At designe en database på det fysiske niveau kaldes en fysisk skema .
2. Logisk databaseskema
Det logiske databaseskema specificerer alle de logiske begrænsninger, der skal anvendes på de lagrede data. Den definerer visningerne, integritetsbegrænsningerne og tabellen. Her udtrykket integritetsbegrænsninger definere det regelsæt, der bruges af DBMS (Database Management System) at opretholde kvaliteten til indsættelse og opdatering af data. Det logiske skema repræsenterer, hvordan data gemmes i form af tabeller, og hvordan en tabels attributter er knyttet sammen.
På dette niveau arbejder programmører og administratorer, og implementeringen af datastrukturen er skjult på dette niveau.
Forskellige værktøjer bruges til at skabe et logisk databaseskema, og disse værktøjer demonstrerer forholdet mellem komponenten i dine data; denne proces kaldes ER modelling .
ER-modelleringen står for entity-relationship modeling, som specificerer relationerne mellem forskellige enheder.
Vi kan forstå det med et eksempel på en grundlæggende handelsapplikation. Nedenfor er skemadiagrammet, den simple ER-model, der repræsenterer det logiske flow af transaktioner i en handelsapplikation.

I det givne eksempel er Id'erne angivet i hver cirkel, og disse Id'er er primærnøgle og fremmednøgler.
Det primær nøgle er bruges til entydigt at identificere posten i et dokument eller en post. Id'erne for de øverste tre cirkler er de primære nøgler.
Det Fremmed nøgle bruges som den primære nøgle til andre tabeller. FK repræsenterer fremmednøglen i diagrammet. Det relaterer en tabel til en anden tabel.
3. Se skema
Visningsniveaudesignet af en database er kendt som se skema . Dette skema beskriver generelt slutbrugerens interaktion med databasesystemerne.
Forskellen mellem det fysiske og det logiske databaseskema
| Fysisk database skema | Logisk databaseskema |
|---|---|
| Det inkluderer ikke egenskaberne. | Det inkluderer attributterne. |
| Den indeholder både primære og sekundære nøgler. | Den indeholder også både primære og sekundære nøgler. |
| Den indeholder tabelnavnet. | Den indeholder navnene på tabellerne. |
| Den indeholder kolonnenavnene og deres datatyper. | Den indeholder ikke noget kolonnenavn eller datatype. |
Databaseforekomst eller databaseskema er det samme?
Begreberne databaseskema og databaseforekomster er relateret til hinanden og nogle gange forvirrende at blive brugt som det samme. Men begge er forskellige fra hinanden.
Database skema er en repræsentation af en planlagt database og indeholder faktisk ikke dataene.
På den anden side, en database instans er en type snapshot af en faktisk database, som den eksisterede på et tidspunkt. Derfor varierer det eller kan ændres efter tidspunktet. I modsætning hertil er databaseskemaet statisk og meget komplekst at ændre strukturen i en database.
strsep c
Både instanser og skemaer er relateret til og påvirker hinanden gennem DBMS. DBMS sikrer, at hver databaseinstans overholder de begrænsninger, som databasedesignerne har pålagt i databaseskemaet.
Oprettelse af skema
For at oprette et skema bruges 'CREATE SCHEMA'-sætninger i hver type database. Men hver DBMS har en anden betydning for dette. Nedenfor forklarer vi oprettelse af skema i forskellige databasesystemer:
1. MySQL
I MySQL , det ' OPRET SKEMA ' sætning opretter databasen. Det er fordi CREATE SCHEMA-sætningen i MySQL ligner CREATE DATABASE-sætningen, og skema er et synonym for databasen.
2. Oracle-database
I Oracle Database er hvert skema allerede til stede hos hver databasebruger. Derfor opretter CREATE SCHEMA faktisk ikke et skema; snarere hjælper det med at vise skemaet med tabeller og visninger og giver adgang til disse objekter uden at kræve flere SQL-sætninger for flere transaktioner. 'CREATE USER'-sætningen bruges til at oprette et skema i Oracle.
3. SQL Server
I den SQL server, opretter 'CREATE SCHEMA'-sætningen et nyt skema med navnet angivet af brugeren.
Design af databaseskemaer
Et skemadesign er det første trin i at bygge et fundament inden for datastyring. Ineffektive skemadesign er vanskelige at administrere og bruger mere hukommelse og andre ressourcer. Det afhænger logisk set af forretningskravene. Det er nødvendigt at vælge det korrekte databaseskemadesign for at lette projektets livscyklus. Listen over nogle populære databaseskemadesign er givet nedenfor:
Flad model
Et fladt modelskema er en type 2D-array, hvor hver kolonne indeholder den samme type data, og elementer i en række er relateret til hinanden. Det kan forstås som et enkelt regneark eller en databasetabel uden relationer. Dette skemadesign er mest velegnet til små applikationer, der ikke indeholder komplekse data.
Hierarkisk model
Det hierarkiske modeldesign indeholder en trælignende struktur. Træstrukturen indeholder rodknuden for data og dens underordnede knudepunkter. Mellem hver underordnede node og overordnede node er der et en-til-mange forhold. Sådanne typer databaseskemaer præsenteres af XML- eller JSON-filer, da disse filer kan indeholde entiteterne med deres underentiteter.
streng i java
De hierarkiske skemamodeller er bedst egnede til at gemme de indlejrede data, såsom at repræsentere Hominoid klassificering.
Netværksmodel
Netværksmodeldesignet ligner hierarkisk design, da det repræsenterer en række knudepunkter og knudepunkter. Hovedforskellen mellem netværksmodellen og den hierarkiske model er, at netværksmodellen tillader et mange-til-mange forhold. I modsætning hertil tillader den hierarkiske model kun et en-til-mange forhold.
Netværksmodeldesignet er bedst egnet til applikationer, der kræver rumlige beregninger. Det er også fantastisk til at repræsentere arbejdsgange og hovedsageligt til sager med flere stier til det samme resultat.
Relationel model
Relationsmodellerne bruges til relationsdatabasen, som gemmer data som tabellens relationer. Der er relationelle operatorer, der bruges til at operere på data for at manipulere og beregne forskellige værdier ud fra dem.
Stjerneskema
Stjerneskemaet er en anden måde at skemadesigne til at organisere data på. Den er bedst egnet til at gemme og analysere en enorm mængde data, og den fungerer på 'Fakta' og 'Dimensioner'. Her faktummet er det numeriske datapunkt, der kører forretningsprocesser, og Dimension er en beskrivelse af fakta. Med Star Schema kan vi strukturere dataene for RDBMS .
Snefnug-skema
Snefnugskemaet er en tilpasning af et stjerneskema. Der er en hoved-'Fakta'-tabel i stjerneskemaet, der indeholder de vigtigste datapunkter og reference til dens dimensionstabeller. Men i snefnug kan dimensionstabeller have deres egne dimensionstabeller.